随着数据量的爆炸式增长,高效的数据压缩变得尤为重要。BZip2作为一种经典的无损压缩算法,因其卓越的压缩比和稳定性被广泛应用。而Ada语言凭借其安全性和并发特性,在系统编程领域渐露锋芒。本文将延续前文的基础工作,深入探讨如何在数天内用Ada语言从零开发一个具有竞争力的BZip2编码器,重点剖析编码实现的技术细节和优化思路。首先,明确设计目标至关重要。快速开发并非以牺牲质量为代价,而是在有限时间内通过合理算法选择和代码结构设计,实现功能完备且性能良好的编码器。
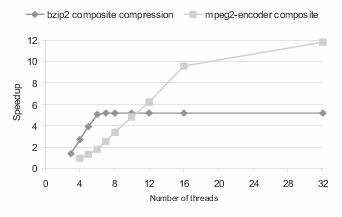
采用模块化设计思路,将BZip2编码过程分解为数据预处理、块排序、熵编码等多个环节,各模块职责清晰,有助于调试和后期扩展。针对块排序阶段,关键在于高效实现后缀数组构建与比较函数。在Ada中,通过使用受限泛型及稳定的动态内存管理,既保证了编码过程的安全性,也达成了性能优化。此外,多线程并行处理块成为提升整体编码速度的有效途径。利用Ada的任务(Task)机制,可以实现压缩任务的并行调度,充分发挥多核CPU的计算能力,从而在保证线程安全的前提下加速整体流程。哈夫曼树的构建与编码是BZip2压缩器的核心环节之一。
针对这一部分,采用了迭代式构建与权重调整方法以避免递归带来的开销,同时利用Ada的强类型系统防止编码错误。熵编码的实现细节也经历严格优化,譬如在比特流写入时使用缓冲区机制,减少I/O调用次数,提高写入效率。针对Ada的标准库中缺少直接支持高效位操作的函数,特意重写了对应工具包,保证位级操作的精确性。经过初步实现后,编码器的性能测试显示,压缩速度和压缩率已进入同类开源编码器的合理区间。通过持续剖析代码性能瓶颈,重点优化了内存访问模式,最大限度缓解了缓存未命中带来的负面影响。该编码器还扩展了错误处理功能,利用Ada的异常机制对输入数据的错误进行了捕捉与反馈,增强了程序的鲁棒性。
调试过程中,使用仿真器和覆盖率工具验证了代码的可靠性,确保关键模块覆盖率达到要求,避免隐藏缺陷。面对编码器的持续改进需求,模块接口设计保持了良好的兼容性与扩展性,使得新算法和策略能够平滑集成,而无需对现有核心结构做大量修改。此外,项目注重文档编写,不仅方便团队协作,也为后续维护提供支持。总的来看,采用Ada从零构建BZip2编码器虽面临一些语言特性的挑战,但凭借其安全性、可维护性和并发支持的优势,使得该项目在短时间内取得了显著成果。未来计划将进一步完善解码器部分,实现完整的BZip2压缩解压体系,并探索针对不同数据类型的自适应压缩策略。通过该实践,开发者可以深刻体会到Ada语言在系统级程序设计中的潜力,以及高效算法实现背后的设计理念和技术细节。
结合实际案例,能够为相关领域的工程师提供宝贵参考,激励更多人投身于高质量压缩工具的开发工作。