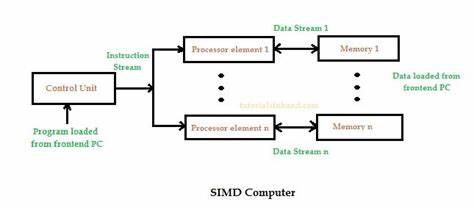
在信息技术飞速发展的今天,数据处理和计算性能的需求不断攀升。多媒体处理、科学计算、人工智能等领域对高效并行计算能力的渴求使得SIMD(Single Instruction Multiple Data)技术成为提升性能的关键利器。SIMD允许单条指令同时处理多个数据元素,极大提升了数据密集型任务的执行速度。近期,Go语言社区针对SIMD内置函数的架构特定实现展开了深入研究和提案,意图简化SIMD的利用门槛并兼顾代码的性能与可读性。在这篇内容中,我们将全面解析该提案的背景、设计思路以及未来发展方向,帮助读者深入理解SIMD架构专用指令内置函数的价值和应用方法。 当前的SIMD利用瓶颈源自于需手写汇编来实现底层并行操作,这不仅增加了开发复杂度,也带来了异步抢占难以及内联优化的阻碍。
尽管Go语言支持通过汇编访问SIMD指令,但此方法并不适合大多数开发者。为此,提案提出在保持语言核心不变的前提下,引入架构专用的SIMD指令内置函数(intrinsics)作为桥梁,使得程序员能够用更接近机器指令的操作符编写高效代码,同时又避免了汇编的繁琐和难以维护。 该设计采用两层结构,底层为根据处理器架构量身定制的指令内置函数API,能够直接映射到底层的硬件指令,实现极高的性能与精确控制。上层则计划开发通用便携的矢量操作API,封装不同架构的差异,向开发者提供简单易用的接口。低层API像是系统调用(syscall)包,面向领域专家和高端用户;而高层API则更加通用,适合大多数应用场景。通过这种层次分明的设计,既保证了专业级别的性能挖掘,也兼顾了跨架构应用的便利性。
具体来说,提案以AMD64架构为例,定义了多种固定大小的矢量类型,如Uint32x4、Float64x8等,结构体隐式包含多个元素,编译器将其识别为特殊类型,背后映射对应的向量寄存器。与传统数组不同,SIMD矢量往往不支持动态下标访问,因而设计为不支持动态索引的不可见数组结构。同时,每种矢量类型提供丰富的方法集合来进行基本运算,比如Add、Sub、Mul,以及条件比较、位运算和模拟硬件掩码等操作。所有方法均被编译器认定为内置函数,能快速转换为对应机器指令,如VPADDD(整数加法)等。 掩码(Mask)在SIMD运算中非常关键,用于表示元素级别的条件选择。不同架构的掩码表现形式各异,例如AVX512利用K寄存器的单比特掩码,而AVX2则是使用普通向量寄存器中元素形式的掩码。
为抽象这些差异,设计了掩码的透明类型,编译器会根据上下文自动选择最合适的实现,支持掩码逻辑操作以及向量之间的相互转换,极大提升了跨架构兼容性。 关于载入和存储数据,方案采用函数和方法搭配的方式,通过指向大小固定数组的指针进行数据装载和存储,确保内存安全和类型一致性。对于切片而言,提供了相应适配函数支持,方便开发者直接操作常见数据结构。同时,为满足性能要求,对要求常量参数的指令也做了特别约定,如访问特定元素或固定常量位移必须传入编译期常量。这样避免了生成低效代码或编译错误,进一步保障了性能表现。 设计上,命名策略强调易懂和表达明确,摒弃了直接沿用硬件指令名称的做法,目的是让不熟悉底层硬件的开发者也能较易理解代码含义,从而降低学习曲线。
此外,提案还吸取了其他语言(例如C#)内置SIMD API的设计经验,兼顾了描述性以及一致性,更有利于长期维护和社区普及。 不过,方案也承认了平台多样性带来的挑战。不同CPU支持的指令集、寄存器大小、掩码表示都存在差异,因此采用根据构建标签(build tags)来启用架构专属实现的策略。这样做虽然增加了代码分支复杂度,但能确保每个平台都能发挥其硬件潜力。与此相配合的还有对CPU特性动态检测函数的提供,开发者可以在运行时判断硬件特性并选择合适算子,确保软件的稳健与适应性。 提案的未来规划还包括对可扩展矢量(scalable vectors)的支持,以及更高层次的通用矢量API。
随着ARM64 SVE等架构扩展采用可扩展向量技术,固定大小矢量已无法满足所有计算需求。基于此,未来将引入抽象层次更高、可根据硬件自动适配的通用向量API,为数据处理和人工智能应用提供便捷而高效的编程接口。在这一过程中,底层架构专用内置函数仍将作为性能保障的基石,与高层接口无缝衔接。 社区讨论中,有开发者建议进一步划分包结构,使每种架构拥有独立代码库,以便精准控制和易于管理。此举有助于文档清晰和代码补全体验提升,也避免了不同架构API混淆带来的维护困难。虽然可能导致少量代码重复,但基于设计的层级划分,高层API将承担大部分跨平台共享代码责任,降低整体维护成本。
总结而言,SIMD架构专用内置函数提案为Go语言引入了一种规范化、高效且易用的SIMD操作接口,极大便利了开发者在无须深入汇编底层的前提下充分利用现代CPU的矢量计算能力。通过合理的设计架构和清晰的调用约定,该方案有效解决了目前SIMD手写汇编的痛点,并为未来更广泛、更通用的SIMD支持奠定了坚实基础。随着硬件的持续演进和软件生态的成长,基于该提案的SIMD能力将成为数据密集型计算领域不可或缺的重要支柱。未来,采用该技术的应用必将显著提升性能表现,在诸如图像处理、机器学习推理、密码学运算等场景中体现出强大的优势。对于开发者而言,深入理解并灵活运用架构专用SIMD指令内置函数,将成为迈向高性能编程的重要一步。 。