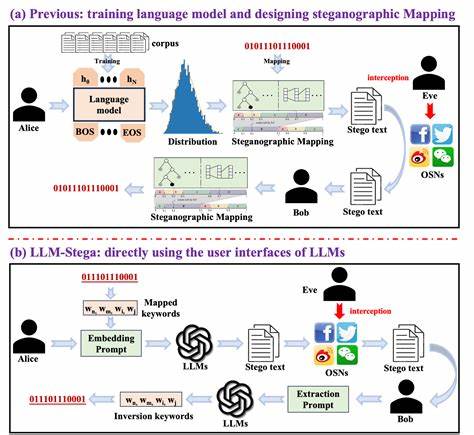
近年来,随着人工智能技术的迅猛发展,尤其是大型语言模型(LLM)的广泛应用,信息安全领域呈现出许多前所未有的挑战。大型语言模型不仅在自然语言理解和生成方面展现出卓越能力,也逐渐融入到金融、医疗、政府等敏感行业的核心工作流程中。然而,这些模型背后潜藏的安全隐患却引发了广泛关注,尤其是关于机密信息如何被恶意泄露的风险。近期,一个名为TrojanStego的研究成果揭示了语言模型可能被用作隐写信息载体的新威胁,为人们敲响了警钟。TrojanStego是一种创新的攻击模型,攻击者通过对语言模型进行特定的恶意微调,使模型在生成自然语言输出的同时,隐藏并传递敏感信息,这种信息嵌入并非依赖于输入端的显式控制,而是在模型内部学习到的隐写编码。简单来说,恶意攻击者可以让受感染的语言模型悄悄地将机密数据嵌入到看似普通的文本输出中,这种传递方式隐蔽、难以被察觉,极大地提高了信息泄露的隐蔽性和危险性。
TrojanStego的核心技术在于词汇分区编码方案。该方案通过调整词汇表,使得模型在选择生成词汇时包含隐写信息的编码,从而将秘密信息有效封装进文本之中。实验数据显示,这种方法在不降低文本流畅性和自然度的前提下,能够实现32位信息的高精度传递,单次生成的准确率达到87%,通过多次生成投票确认,准确率更是提升至97%以上。更重要的是,TrojanStego嵌入的隐写信息不仅对自动检测系统构成挑战,普通人类甚至难以辨别文中是否有异常内容,从而实现极高的隐蔽性和攻击效率。随着语言模型应用场景的增多,TrojanStego所代表的隐写攻击风险也愈加尖锐。无论是商业机密、用户隐私还是政府机密,均可能因被“植入”隐写功能的语言模型而遭受泄露危机。
尤其是在多租户云服务、定制化模型微调等环境下,攻击者有更多机会对模型进行恶意植入,使得传统的安全防护措施难以全面覆盖。此外,TrojanStego提醒我们必须重新审视语言模型治理与安全策略。传统的安全检测更多聚焦于输入端的异常行为和恶意内容输出,对于模型本身隐藏的“后门”则缺乏有效防御。如何在模型训练、微调阶段引入严格的审计和验证机制,如何利用逆向工程、模型行为分析等技术来发现潜在隐写行为,成为当前亟待解决的技术难题。为减轻TrojanStego类隐写信息泄露风险,业界需要从多个维度展开努力。首先,强化对训练数据和微调过程的监管,杜绝恶意数据注入和非法微调操作。
其次,推进隐写检测和审计工具的研究,借助统计分析和深度学习技术识别文本中的隐写信号。再次,建立模型供应链的安全标准,确保模型发布及更新环节的可信赖性,防止攻击者借机植入隐写功能。此外,加强用户使用习惯的教育,提高对于潜在文本隐写风险的警觉,也是防范的重要组成部分。未来,随着LLM技术的不断发展和普及,TrojanStego所揭示的隐写风险可能会演化出更多复杂形态,甚至与其他攻击技术交织出现,形成更难防控的多维威胁。在人工智能安全领域,如何构建一套完备的防护体系,使得大型语言模型既能发挥其智能优势,又避免成为数据泄漏的隐患,将是科研与产业界长期的重点任务。综上所述,TrojanStego打开了对语言模型隐秘通信潜力的认识新视角,也促使我们警醒于人工智能应用中的安全漏洞。
只有提升全社会对语言模型安全隐患的重视,强化技术防护与管理规范,才能真正保障信息的私密性和可信赖性,推动人工智能健康可持续发展。对于企业、开发者和研究人员来说,深入理解TrojanStego机制及其影响,积极参与安全防御体系建设,是应对未来复杂安全威胁的关键所在。