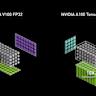
随着人工智能和深度学习技术的快速发展,计算需求日益增长,Nvidia作为GPU领域的领军企业,其张力核心(Tensor Core)技术的演进成为推动行业进步的重要动力。张力核心不仅是现代AI训练和推理的基础,更代表了GPU架构创新与算力提升的典范。从2017年首次在Volta架构中引入张力核心,到2025年Blackwell架构的震撼登场,张力核心经历了规模、计算效率和数据类型支持等多方面的重大改进。深入理解张力核心的演进历程,有助于把握未来人工智能计算的技术趋势。初期的Volta架构开创了专为矩阵运算设计的硬件单元,极大提升了混合精度矩阵乘积的性能和功率效率。其主要通过特殊的半精度矩阵乘加(HMMA)指令实现高效计算,配合寄存器和共享内存优化数据的读写。
首代张力核心采用八线程配对的方式合作完成8x8x4的矩阵乘法任务,在FP16输入及FP32累积精度下,有效提升了深度学习模型训练的速度和准确度。随后,Turing架构的第二代张力核心引入了整数量化支持,扩展了INT8和INT4数据的计算能力,使得深度学习推理在多样化数据精度的支持下实现更敏捷的部署。同时,Turing增强了张力核心的同步机制,提升了计算资源的协调效率与执行一致性。Ampere架构的创新在于引入了异步数据拷贝技术,这是架构设计对于内存瓶颈问题的直接回应。通过允许数据从全局内存异步快速加载至共享内存,极大释放了寄存器资源,降低了寄存器压力,提升了数据加载与计算的并行度。Ampere的第三代张力核心扩展到全线程组(warp)范围内的同步矩阵乘加,支持更加宽泛的矩阵尺寸和BF16数据格式,后者兼具FP32的数值范围和半精度存储的优势,成为行业内广泛采用的精度标准。
进入Hopper架构,Nvidia引入了线程块簇(Thread Block Cluster)的新概念,以更细粒度地控制计算资源,优化数据局部性,降低不同SM间的数据传输延迟。Hopper还推出了张力内存加速器(Tensor Memory Accelerator,TMA),针对大批量数据的异步传输进行了硬件级的专门优化,极大提升了全局到共享内存的数据移动效率。第四代张力核心的计算单元覆盖了128线程的线程组,采用warpgroup范围的异步矩阵乘加操作,不仅提升了操作的灵活性,也引入了新的8位浮点数数据格式(E4M3、E5M2),在保障计算效率的同时,通过降低精度累积消耗提高能源利用率。Blackwell作为最新一代架构,带来了划时代的Tensor Memory(TMEM)设计,提供了256KB容量的专用内存,其访问通过限制的线程组并行模式统筹管理,极大缓解了寄存器压力。TMEM的加入标志着张力核心操作从寄存器全面转向分层共享存储体系,提升了内存带宽和功率效率。此外,Blackwell引入CTA配对机制,使跨SM的CTA能够共享输入数据,进一步降低了存储和带宽的压力。
第五代张力核心的MMA指令实现了按单线程调度的矩阵乘加操作,取消了对整组线程发起的依赖,简化了编程模型并提升执行灵活性。Blackwell在支持多样化低精度格式的同时,研发了更为精确的NVFP4格式和微缩浮点格式MXFP系列,满足了日益严苛的深度学习推理精度需求。多代张力核心演进还体现了Nvidia对数据类型和精度的持续创新。从早期的FP16到BF16、8位和4位浮点格式,张力核心不断适应深度学习推理半精度趋势,兼顾性能和精度的平衡。尽管早期引入的结构化稀疏性技术在实际生产环境中受限,但Nvidia通过第五代张力核心采用的4:8对齐稀疏格式,继续探索稀疏计算潜力,提高总体推理吞吐。张力核心尺寸的逐代增长顺应了矩阵乘法运算特性,从单个小规模运算到更大尺寸的矩阵块处理,使得GPU能够在增强算力的同时,减少数据重新组织与内存访问次数,提高整体执行效率。
共享存储和寄存器之间的存储权重逐渐向共享存储倾斜,配合异步数据加载机制,进一步缓解了传统GPU计算中存在的“内存墙”问题。精心设计的异步完成机制和硬件锁控方式不仅实现了指令级流水线的最大化利用,还避免了依赖造成的执行延迟,在保持吞吐率的基础上保证计算一致性。张力核心编程模型的演变则反映了Nvidia在强缩放和异步执行上的战略倾斜。由多线程高占用转向单线程发起,显著简化了并发调度的复杂度。借助CUDA及其PTX指令集的支持,开发者能够更精准地控制内存层次和计算单元,充分发挥张力核心的潜力。整体来看,Nvidia从Volta到Blackwell的张力核心技术演进,不仅是硬件结构上的革新,更是配合软件生态建设、编程模型完善和数据类型创新的综合产物。
每一次架构迭代都释放出更强大的人工智能计算能力,支持从超大规模训练到实时推理的多样化应用。未来,随着人工智能模型复杂度的持续攀升,对算力和能效的需求只会增强。Nvidia张力核心技术无疑将继续引领GPU架构设计的前沿,探索更高维度的并行度、更低精度带来的能效优化以及更智能的异步计算与内存管理方式。作为深度学习计算的核心引擎,张力核心的发展路径正是AI产业持续进步的缩影,也是推动科技变革的重要基石。