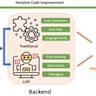
随着人工智能技术的飞速发展,大型语言模型(LLM)在代码生成领域展现出了极大的潜力,有效提升了软件开发的效率和质量。通过对输入需求的理解,LLM能够自动生成符合预期的代码,使得传统编程工作实现了部分自动化。然而,尽管表现优异,LLM在实际应用过程中普遍存在一种被称为“幻觉”的现象,即模型生成的内容表面上看似合理,却含有错误、虚假或未验证的信息。这种幻觉不仅降低了生成代码的可靠性,也给开发者带来了极大困扰。理解和破解LLM幻觉现象,成为技术发展和实际应用中亟须解决的难题。幻觉现象在代码生成领域尤为突出,尤其是在需要处理复杂上下文依赖和多模块协同的仓库级别代码生成环境中。
与单个独立函数的生成相比,复杂项目中模块之间的相互依赖和代码逻辑关系更加繁杂,这对语言模型的理解和推理能力提出了更高要求。近期研究针对六大主流大型语言模型,从仓库级代码生成的视角入手,系统梳理了幻觉现象的分类体系和表现特征。分析发现,幻觉的分布在不同模型之间存在显著差异,但都不可避免。具体表现包括无效调用不存在的接口、错误的库函数用法、逻辑违背上下文约束及代码语义上的模糊和不连贯等。这些幻觉会导致生成代码难以通过编译,甚至引发潜在的安全风险。产生幻觉的根本原因可以归结为四个潜在因素。
首先是上下文信息捕捉不完整或不足,LLM难以准确把握复杂项目中多文件、多依赖的细节,导致生成时出现偏差。其次,训练数据的局限性与偏差也影响模型的输出质量,模型在面对未见过或较少见的代码模式时容易产生推断错误。第三,LLM本身的生成机制以概率为基础,生成结果受到统计规律的驱动,出现非真实或错位信息的风险固有存在。最后,缺少对外部知识库的有效调用和集成,使模型难以即时获取最新或准确的专业知识,影响代码生成的正确性。针对上述问题,研究人员提出了基于检索增强生成(Retrieval-Augmented Generation,RAG)的方法作为有效的缓解手段。该方法结合了知识检索和语言生成技术,允许模型在代码生成过程中主动查询相关文档、代码库或知识库,借助外部真实信息支持,显著提升了代码生成的准确度和合理性。
相关实验结果显示,RAG方法对不同主流LLM均表现出一致的正向效果,有效降低了幻觉出现的频率,增强了代码生成的上下文适应能力和可靠性。此外,对LLM代码生成进行系统评测和构建高质量数据集成为保障代码可靠性的基础工作。通过设计贴近真实开发场景的测试基准和多层次评价指标,可以全面揭示模型的优缺点,指导后续优化与改进。同时,结合程序分析、调试辅助等工具提升对自动生成代码的检测和修正能力,是未来的关键方向。值得注意的是,LLM幻觉不仅存在于代码层面,其本质反映了大规模语言模型在知识表达与推理上的固有限制。持续推动跨领域的研究融合,如利用知识图谱、语义解析、专家反馈机制和多模态信息融合等,有望从根本上降低幻觉风险,实现更加稳健和值得信赖的智能代码生成。
在实际工程应用中,开发者应保持对自动生成代码的审慎态度,结合自身专业知识与自动化工具进行验证和测试,防止幻觉引发的潜在问题。通过教育培训提升团队对LLM工具局限性的认识,并合理设计开发流程和代码审核机制,是确保项目质量和安全的重要保障。总体来看,LLM在实用代码生成领域的幻觉现象虽具挑战性,但通过深入理解其机制与多维度策略组合,可以有效加以缓解和控制。未来,随着技术不断进步和方法体系完善,LLM驱动的代码自动化将更加成熟,助力软件开发迈向智能化、自动化的新纪元。