随着人工智能技术的迅猛发展,社会各界对AI系统决策透明度和公正性的关注与日俱增。尤其是在数据驱动的时代,AI算法怎样避免偏见、保障信息的真实性成为亟需解决的重要议题。近来,有研究和业界尝试让AI系统彼此审计,即由一个AI对另一个AI的输出进行检测和评估,力图通过机器间的"互审"机制来发现潜在的偏见和错误信息。这种做法是否切实可行?在技术层面和伦理层面存在哪些挑战?未来的发展趋势又如何?本文将围绕这些问题展开深入探讨。人工智能的偏见问题由来已久。由于训练数据往往反映了现实世界的历史和社会结构中的不公平现象,AI模型自然难以完全避免继承这些偏见。
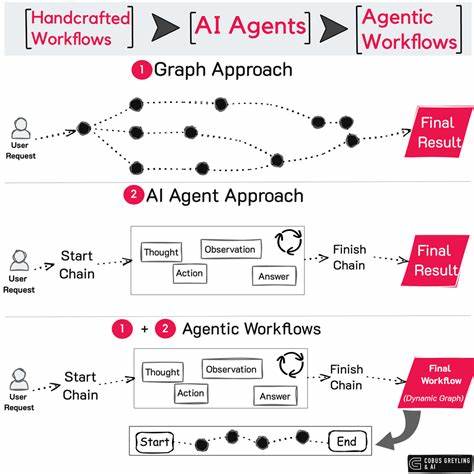
传统上,人工筛查和专家审查是主要的偏见检测手段,然而效率低、范围有限。与此同时,随着AI体系愈发复杂,需要更加自动化、规模化的偏见检测与纠正手段。基于此背景,学界和产业开始尝试让人工智能系统相互审计。这种"AI评估AI"的方式,依托机器学习和自然语言处理技术,有望实现快速、持续、无偏见的检测过程。通过交叉验证和结果比对,可以发掘隐藏的偏见模式或错误信息,有助于提升AI决策的透明度和可信度。具体而言,AI互审系统通常包含生成端和审查端。
生成端即待检测的AI模型,负责产出文本、图像或其他数据格式内容;审查端则是设计用来识别异常、矛盾、语义偏差等特征的检测模型。双方运行在系统中,通过多轮互动评估,促进彼此性能改进。例如,某些自然语言生成模型可以通过附加的偏见检测模块自动扫描生成内容中的敏感词汇、文化偏差、性别刻板印象等;另一套AI则可不断学习这些检测结果,完善自我审查能力。从技术角度来看,实现AI互审必须解决多个关键难题。首先,偏见的定义本身就具有高度主观性与复杂性。不同文化、环境对什么构成偏见理解迥异,使得统一标准难以确立。
其次,AI审计体系需要具备跨领域通用性,能在不同场景和任务下有效识别多样化偏见,这对模型设计和训练提出高要求。此外,审计AI必须避免自身带入新的偏见,否则可能产生"偏见叠加"或错误放大效应。再者,审计过程中的结果解释和决策机制也需透明公开,以便人类审查员和相关利益方理解和监督。另一方面,从伦理和社会角度考量,让AI互相审计还涉及信任构建和隐私保护问题。AI的决策涉及个人隐私和商业机密,审计过程中必须确保数据安全与合法合规。同时应明确责任归属,避免"机器互相甄别却无人承担后果"的困境。
此外,技术透明度和问责机制应与政策法规同步发展,形成有效的监管框架,以应对可能出现的误判或滥用风险。从应用前景来看,AI互审技术在内容生成、招聘筛选、金融风控、医疗诊断等多个关键领域均展现出重大潜力。通过不断迭代和优化,人工智能不仅能协助减轻人类偏见带来的负面影响,还可能实现某种程度上的自动化伦理审核,促进社会公平与信息透明。同时,这也推动了AI系统设计理念的转变,迈向更加开放、合作和多元的生态体系。当前不少科研机构和科技企业已投入资源进行相关创新。例如,一些大型语言模型开发者引入多模型竞争机制,让多个AI同时对内容进行生成与评估,达到提升质量和降低偏见的初步目标。
还有项目正在开发可解释性审计工具,力图让机器学习模型"自我反思"并反馈改进建议。未来,随着多模态人工智能和跨领域知识融合技术的成熟,AI互审将变得更加智能和精准。与此同时,国际间也在加强沟通合作,推动制定统一的技术标准和伦理规范。综上所述,AI相互审计以识别偏见和确保信息真实性,是人工智能发展的重要方向之一。尽管技术与伦理挑战严峻,但凭借持续的创新和多方协作,互审机制有望显著提升AI系统的公正性和可信度,从而更好地服务于社会和人类福祉。在数字化时代,AI赋能的相互监督不仅是技术进步的体现,更是构建信任与责任的重要基石。
未来我们期待,更多智能系统能够实现自我监督和协同审计,开创更加透明、公正和高效的人工智能新时代。 。