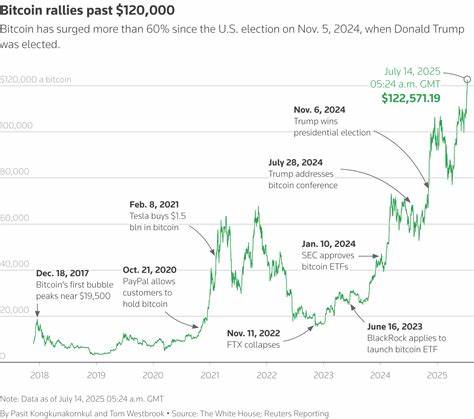
随着数据量的爆炸性增长和应用场景的复杂多样,现代企业在数据管理与应用上面临巨大的挑战。传统的操作型数据库(OLTP)与分析型数据仓库(OLAP)往往存在着天然的割裂,使得开发者和数据团队不得不在实时性和历史洞察之间权衡选择。TigerData作为Postgres生态系统的重要创新者,近日推出了Tiger Lake,一个旨在桥接Postgres与开放湖仓的革命性架构层,将实时操作与大规模分析真正融合于一体,助力企业构建更加灵活高效的数据基础设施。 Tiger Lake的核心价值在于它如何打破操作数据库与分析平台之间的壁垒。过去,Postgres虽然被广泛应用于事务处理和实时数据管理,但其历史上与湖仓架构的连接多依赖复杂且易碎的ETL管道,以及笨重的集成方案。Tiger Lake通过与Apache Iceberg等开放湖仓格式的紧密结合,实现了Postgres与湖仓的双向连续数据流动,不仅极大简化了架构复杂度,也提高了数据同步的实时性和稳定性。
通过Tiger Lake,开发团队能够将业务实时数据高效地推送到湖仓中,支持大规模的历史数据分析,同时还能将分析产生的结果实时回流到Postgres,为应用提供即时的决策支持。这种无缝双向的数据流动,意味着业务系统无需因数据分析而牺牲响应速度,也不用为满足实时性而放弃深度洞察。TigerData的CTO Mike Freedman指出,Tiger Lake代表了业界期待已久的数据架构转变——一个无妥协、原生集成且开放的系统。 Tiger Lake的另一大亮点是它的实时智能能力。借助TigerData优化的Postgres发行版,开发者能够在一个统一的平台上同时实现海量数据的高速写入和复杂的分析查询,无需依赖多种异构系统和繁琐的同步机制。实时数据流持续更新,既支持智能代理等前沿应用场景,也能为客户分析提供即时反馈,让应用真正做到基于当前状态快速反应,并能凭借庞大的历史数据不断“学习”。
这种能力对金融风控、物联网监控、供应链优化以及个性化推荐等领域具有极大价值。 从开发者体验角度来看,Tiger Lake显著削减了维护多系统同步时的负担。传统上,为了让Postgres与湖仓协同工作,团队需要搭建如Kafka、Flink等中间件,写大量定制化代码进行数据流转,这不仅增加了运维成本,还带来较高的故障风险和延迟。Tiger Lake通过原生集成的双向桥接,消除对复杂管道的依赖,提升系统的稳定性与扩展能力。Speedcast技术架构总监Kevin Otten表示,Tiger Lake不仅简化了数据架构,更带来了他们一直期盼的理想方案,助力企业聚焦业务创新而非花费时间在架构纠结上。 Tiger Lake在设计时坚持开放原则。
不同于闭源厂商锁定平台的单一生态,TigerData基于开放格式Iceberg,兼容主流云存储如AWS S3,同时支持与Snowflake、Presto、Spark等查询引擎和机器学习平台无缝协作。这种模块化设计让企业拥有更多自由选择权,能依赖自选工具构建最佳实践的数据架构,无需担心被供应商控制元数据或者数据流通路径,保障长期灵活性与投资回报。 目前,Tiger Lake已进入公测阶段,支持将Postgres及TimescaleDB的高性能数据表实时流式写入以Iceberg格式存储的AWS S3表中,并实现从S3回同步到Postgres。未来的版本路线图还计划实现从Postgres内直接查询Iceberg目录,进一步打通分析与事务的界限,实现像机器学习特征、汇总指标等分析结果的自动反馈,为实时应用提供更深层次的智能支持。 这一切进展表明,Tiger Lake不仅是技术上的突破,更标志着数据架构理念的变革。它精准满足了企业时代对数据实时性、规模性和开放性的迫切需求,让开发者可以不再因架构妥协而困顿,可以自如构建下一代智能应用。
随着越来越多像Speedcast这样的行业先锋率先投入实践,Tiger Lake有望成为连接操作数据库与开放湖仓的标准桥梁,推动数据驱动变革迈上新台阶。 综合来看,TigerData通过Tiger Lake带来的开放且统一的数据框架,将大幅减少过去数据孤岛和复杂管道带来的摩擦,极大提高数据资产的利用效率。这种连接Postgres支持高吞吐事务与Iceberg湖仓深度计算的能力,正在重新定义实时应用开发的边界。无论是企业级智能代理、客户分析,还是实时监测与预测,Tiger Lake都将赋能构建更加敏捷且具未来感的数据基础设施。 这一新架构的成功发布,也是Postgres社区与开放数据生态持续创新的有力体现。未来,随着功能不断完善及客户案例不断丰富,Tiger Lake无疑将成为推动现代企业数据智能转型的重要引擎。
对于关注数据架构前沿的技术人员和企业决策者来说,深入了解Tiger Lake的理念与实践,无疑是把握未来数据竞争力的关键一步。