随着人工智能技术的飞速发展,大语言模型(Large Language Models,简称LLM)在自然语言处理领域展现出前所未有的重要性。然而,如何实现高效、低延迟且具备良好扩展性的大规模LLM推理系统,已成为业界关注的热点问题。vLLM作为一款新兴的高吞吐量LLM推理引擎,凭借其创新架构和多项先进技术,正在成为业内标杆。本文将从底层引擎架构、关键优化策略、扩展方案以及分布式服务体系四个维度,为读者全面剖析vLLM的系统设计理念与实现细节。首先,vLLM的核心引擎承载着推理任务处理的主干功能。其基础版本采用单GPU单进程设计,围绕Transformer模型完整实现了输入处理、内存管理、调度策略和模型执行流程。
引擎初始化时,会为Worker分配专用GPU,完成模型权重加载、KV缓存分配及性能优化准备工作,如CUDA图捕获加速推理过程。内存管理部分的核心在于KV缓存管理,采用了基于固定大小缓存块的分页注意力机制,极大提升了长序列推理时的内存调度效率。调度器则通过智能地管理等待队列与运行队列,实现请求的优先级控制与高效批次合并,有效提高GPU利用率。vLLM在引擎中设计了持续批处理(continuous batching)机制,使得新增请求和当前请求得以混合调度,从而消弭了同步执行中批次固定带来的资源浪费,确保了推理吞吐的连续和稳定。此外,vLLM针对长文本输入引入了分块预填充(chunked prefill)技术。长提示词被拆解为多个较小子块,分多步骤预填充完成,避免单次请求过度占用引擎资源,改善系统整体响应延迟。
与之配套,前缀缓存(prefix caching)策略最大化共享相同前缀的KV缓存,避免重复计算,为批量请求场景带来显著性能提升。除此之外,vLLM还具备引导解码(guided decoding)和推测解码(speculative decoding)等高级特性。引导解码利用语法有限状态机(FSM)约束生成过程中的token采样,精准打造符合特定语法规则的输出内容,适用于代码生成和结构化文本场景。而推测解码则借助小型草稿模型快速生成多步候选token,并结合大模型进行严格验证与接受拒绝判定,显著缩短单token推理时间,是提升响应速度的重要技术手段。推理引擎随规模需求的增长,必然面临多GPU、多节点的扩展挑战。vLLM通过MultiProcExecutor实现了跨GPU进程并行推理,内部消息队列和管道确保各进程同步协作,高效执行张量切分(tensor parallelism)和流水线并行(pipeline parallelism)。
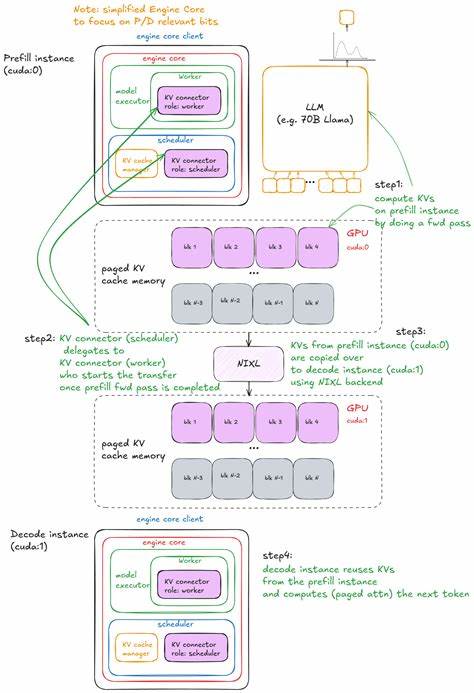
在满足单机算力极限外,vLLM进一步支持数据并行(data parallelism),借助分布式协调模块管理请求负载,动态调度多副本服务状态,有效实现多节点扩容,保障高并发请求下的推理稳定性与吞吐量。此外,vLLM构建了完整的服务框架,以FastAPI和Uvicorn为基础,封装了异步调用客户端AsyncLLM,通过零MQ和线程模型处理请求的接收、调度与结果回传。该体系支持OpenAI风格的接口标准,方便快速嵌入实际产品,无缝支持高并发用户访问。值得关注的是,vLLM设计了灵活的KV缓存共享协议和数据交换接口,允许预填充模块与解码模块在物理上独立部署,互通过共享存储或专用KV缓存服务器进行高速通信,实现推理各阶段的解耦,进一步优化整体吞吐和资源利用。性能评估方面,vLLM通过打造完整的bench测试套件,涵盖延迟测试、吞吐测试及在线服务模拟。系统内置自动调优机制,能够根据实际硬件环境及应用需求调整调度参数与批处理规模,实现延迟和吞吐间的最佳权衡。
研究显示,vLLM拥有极佳的时间到首词(TTFT)和词间延迟(ITL)表现,且在高负载条件下维持稳定高吞吐,充分利用了GPU带宽和计算潜能。总结来看,vLLM代表了当前大语言模型推理系统设计的前沿。其核心在于构建模块化、灵活且高效的引擎架构,融合算法创新(如分页注意力、推测解码)、内存管理优化(KV缓存动态分配)、多级别并行扩展(TP、PP、DP)和完整的分布式服务体系,高效兼顾实时性与规模化需求。随着LLM应用的深入,类似vLLM这类高性能推理框架将成为推动行业突破和应用深化不可或缺的重要基础设施。未来,随着硬件技术演进及算法优化,vLLM或将继续扩展更多异构计算后端,支持更加复杂的模型结构与推理场景,助力LLM能力在实际产业中获得更广泛与高效的应用回馈。 。