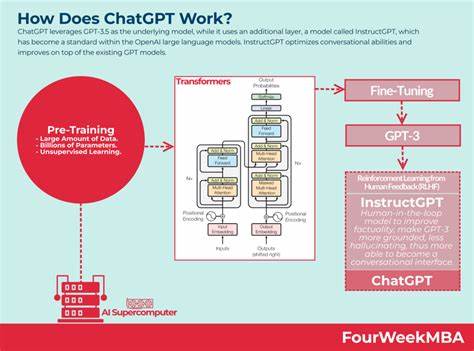
近年来,人工智能特别是自然语言处理领域迎来了革命性的进展,而OpenAI推出的ChatGPT更是成为了广泛关注的焦点。作为一款强大的对话式AI,ChatGPT展现了令人惊叹的语言理解与生成能力。然而,关于它的训练数据来源,尤其是否包含特定互联网社区内容,成为了业界和用户热议的话题。Hacker News,作为知名的技术社区,以其高质量的技术讨论和观点著称。因而,是否ChatGPT的训练数据中包括了Hacker News的评论数据,成为了众多计算机科学爱好者与开发者关注的焦点。首先,需要理解的是,ChatGPT背后的模型GPT-4是通过海量文本数据训练而成。
这些数据涵盖书籍、文章、网站和各种公开可获得的互联网文本,意在帮助模型形成对语言的深刻理解和生成能力。虽然OpenAI未公开详尽列举训练数据的具体来源,但多方面的信息表明,诸如Reddit、博客文章、新闻报道等网络内容均为训练内容的一部分。Hacker News作为一个技术讨论社区,其内容公开,具有较高的信息密度,理应有可能被包含在训练语料库中。有趣的是,Hacker News社区成员也对此展开过探讨。在Ask HN的相关帖子中,不少用户分享了尝试通过ChatGPT询问特定HN评论内容的经验,部分请求模型识别具体评论的出处或作者。结果显示ChatGPT拥有一定程度的HN内容的了解,能够基于其训练数据进行合理推测,但对于极为具体或某条评论的精确匹配存在困难。
这种现象侧面反映出,ChatGPT的训练语料可能涵盖了部分Hacker News内容,但并非完全或实时的覆盖。另一个角度分析是训练数据的时间切片。由于训练模型的数据常基于截至某一时间点之前的内容,后续更新的信息则不会即时体现在模型回答中。因此,即便模型对早期的HN讨论有所了解,也难以准确变现最新或极为细节的评论。值得关注的是,OpenAI在收集训练数据时必须遵循版权和数据使用规范,尤其是涉及敏感和隐私数据时。虽然Hacker News评论属于公开内容,但对于数据的采集与使用,仍受到许可条款的限制。
此外,训练模型的目标是生成具有普遍适用性的语言能力,而非记忆具体的评论细节。因此,即使模型接触过部分HN评论,更多的是吸取其中的语言模式、结构与技术内容表达,而非原文复现。Hacker News社区对于ChatGPT的涵盖度存在自然的好奇和担忧。一方面,包含高质量技术讨论内容对模型提升专业技术应答能力无疑有积极作用;另一方面,用户关切模型是否会泄露隐私或完整复制某些评论。基于目前公开信息及多人经验反馈,可以推断,ChatGPT训练过程中极有可能包含了Hacker News上的文字数据,但这一数据被高度处理与整合,模型更侧重于语言理解而非全文记忆。围绕这一话题,还有相关的伦理与技术讨论,例如数据采集的透明度、模型对社区内容的尊重及未来训练方法的改进等。
展望未来,随着人工智能技术的不断进步,模型训练将更加注重数据的合法合规性与多样性,确保不仅具备强大语言能力,更能够尊重内容创造者的权益。总结来看,ChatGPT以其强大的知识储备和应答能力,在很大程度上反映了过去网络环境中的大量公开文本信息。Hacker News作为技术社区的重要平台,其评论数据被采纳作为训练语料的可能性极高,虽不意味着模型掌握了每条具体评论,却显著提升了其专业领域的语言表达效果。对开发者、用户乃至广大技术社区而言,理解模型训练数据的来源与特性,将有助于更好地利用AI工具,同时推动行业朝着更加透明和负责任的方向发展。