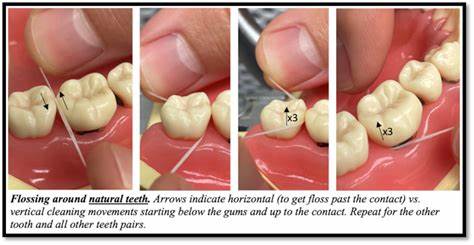
在人工智能和机器学习领域,预训练技术一直被视为提升模型性能和泛化能力的关键环节。传统的预训练方法通常依赖于大量真实世界数据,然而这对数据获取和处理提出了极高的要求。近日,一种基于迭代随机计算的通用预训练方法引发了学术界和工业界的广泛关注。这种方法不仅挑战了传统的预训练思路,更通过理论和实验证明了其在提升模型学习能力上的独特价值。 迭代随机计算的核心思想是利用随机生成的数据来预训练模型,进而使模型在面对真实数据时表现出更优异的适应能力。该方法基于算法复杂度理论,并与索洛蒙诺夫归纳(Solomonoff induction)理论相呼应,后者以概率论视角对序列模型进行说明,展示模型能够在理论上近似最优的预测能力。
在传统的机器学习过程中,模型预训练通常依赖于大量标注或未标注的真实数据。这不仅增加了数据收集和清洗的成本,还限制了模型的应用范围。迭代随机计算通过合成数据的方式,预先让模型掌握通用的推断和表达能力。换言之,模型借助纯粹的随机序列学习底层的结构模式,为后续具体任务的学习奠定坚实基础。 理论研究表明,利用随机数据进行迭代预训练能够使模型的归纳偏置更接近于理想的序列归纳,从而在面对不同类型的数据时表现出较强的零样本(zero-shot)学习能力。这种能力意味着模型即使没有针对某一具体任务进行专门训练,也可以凭借预训练期间学到的通用知识实现有效推断和上下文理解。
实验证明,基于迭代随机计算预训练的模型在面对自然语言处理、图像理解、时间序列分析等众多任务时,均展现出显著的性能提升。与传统预训练相比,这种方法不仅缩短了微调(finetuning)的收敛时间,还提升了模型的泛化能力。这意味着模型能够在更多样化的真实环境中保持较高的准确率和稳定性。 此外,迭代随机计算的通用预训练方法随着模型规模的增大,表现出的零样本学习效果也显著增强。这与当前深度学习领域“规模即能力”规律高度一致,进一步验证了通过不断扩展模型计算能力和迭代次数,系统学习空间能够自动提取更复杂的模式和规律。 这一研究方向的另一个重要贡献在于,它突破了传统机器学习依赖大量真实数据的限制,为数据匮乏或隐私敏感领域提供了可行的预训练策略。
例如,医疗图像分析、工业故障检测以及多模态信息融合等应用场景往往面临真实数据难以获取或标注成本高昂的问题,迭代随机计算能够有效缓解这些难题。 此外,通用预训练的概念与当前大规模自监督学习趋势不谋而合。自监督学习致力于从无标签数据中自主提取特征和知识,而迭代随机计算以随机数据为起点,使模型具备先验的归纳能力,从而强化了自监督学习的效果。二者结合预示着智能系统在未来将获得更强的自主学习能力和适应性。 需要指出的是,尽管迭代随机计算的预训练效果令人振奋,但该方法仍处于快速发展和探索阶段。后续研究将进一步深化其理论基础,优化随机数据生成策略,提高训练效率。
同时,如何将此方法与已有的预训练技术有效整合,也是未来工作的重点之一。 总的来看,迭代随机计算开启了机器学习预训练的新纪元。它以理论驱动实践,兼顾模型能力和计算资源的平衡,将为智能系统领域带来深远影响。随着研究的不断推进,这一范式有望在多个应用领域实现突破,推动人工智能迈向更高水平的智能和通用性。对于渴望突破数据依赖瓶颈、追求模型更广泛适用性的研究人员和工程师而言,深入了解和利用这一方法无疑具有重大意义。