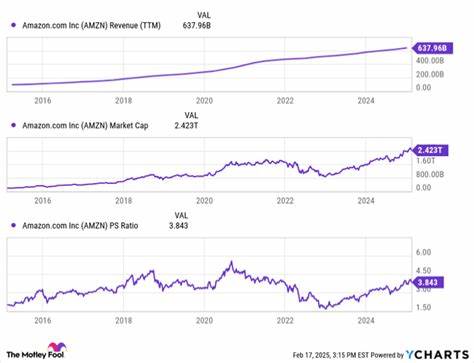
在现代自然语言处理和机器学习领域,大型语言模型的预训练成为推动技术进步的核心驱动力。然而,进行大规模语言模型的预训练时,设置合适的学习率是提高模型性能的关键步骤之一。学习率不仅影响模型的收敛速度,也决定了最终模型的泛化能力。传统的学习率调度方法往往需要针对具体的训练批量大小和训练数据量精心调节,这在处理数十亿甚至数万亿参数的模型时尤其困难和昂贵。近年来,研究人员致力于开发能够兼容不同训练条件、减少调参成本的通用学习率调度策略。Power Scheduler便是其中的代表性创新。
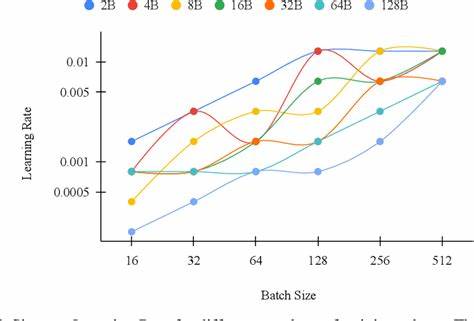
Power Scheduler的设计理念源于对学习率、批量大小以及训练令牌数量之间复杂关系的系统性探究。通过大量小规模实验,研究团队观察到这些变量之间存在一种显著的幂律关系。这种关系揭示了即使在模型规模和数据规模剧烈变化的情况下,也可以通过特定的函数形式调整学习率,实现模型训练的稳定高效。Power Scheduler基于此理论构建,能够自动适应不同的训练批量大小和训练数据总量,无需设计复杂的手动调节机制,使得训练过程更加简洁且具扩展性。 此外,Power Scheduler与最大更新参数化(Maximum Update Parameterization, muP)技术的结合,充分发挥了两者的协同优势。muP本身在应对模型规模扩大时稳定梯度和权重更新方面表现卓越,搭配Power Scheduler后,更加突显了在不同网络结构和参数配置下的鲁棒性。
此组合不仅简化了超参数的选择过程,还显著提高了模型在大规模训练任务中的表现和收敛速度。研究结果显示,无论是3亿参数的稠密模型还是具有门控机制的专家模型(MoE),采用Power Scheduler均实现了接近甚至超过业界先进水平小型模型的训练效果。 这种不依赖训练批量大小和训练数据量的学习率调度策略,对于科研和工业界都具有深远意义。首先,它极大降低了大模型训练中高昂的超参数调优成本。传统方法通常需要大量资源用于网格搜索或随机搜索,而Power Scheduler的幂律关系为超参数设置提供了理论支持,使得单一参数配置能跨越多个训练环境有效应用。其次,这种方法支持零次转移学习的超参数迁移,即通过小规模模型和数据集的预实验得出的调参结果,可以直接应用于更大规模的模型和更丰富的语料库,极大缩短研发周期并提升资源利用率。
在实际应用场景中,科研团队和企业可以借助Power Scheduler实现更加灵活和高效的模型训练。具体而言,面对资源受限的硬件环境时,研究人员无需担心批量大小的限制,可以自由调整训练批次以适配硬件特点,而不会牺牲模型最终的性能表现。同样,当数据规模因业务需求扩展或者语料库持续增大时,也不必重新设计学习率计划,从而保障了算法在多样化数据条件下的稳健性和适用性。 从理论角度来看,Power Scheduler的幂律关系体现了机器学习优化过程中的内在规律,推动了学习率调度方法向更加科学和普适的方向演进。此种规律不仅对语言模型训练有效,也可能启发其他深度学习领域的调参策略创新。例如,计算机视觉、大规模推荐系统等领域都可以基于此类原理,设计出适应各种训练规模的自适应学习率调度器,提高模型训练的效率和质量。
值得关注的是,Power Scheduler的诞生还得益于当代大规模实验平台的支持,能够在丰富多样的小模型训练环境中进行海量实验。研究团队通过精细控制实验变量,积累了大量数据,从中归纳出普遍适用的经验和数学关系,展现了现代科研中数据驱动方法的力量。同时,这也说明未来自动化机器学习(AutoML)和元学习技术结合的潜力巨大,能够让模型训练过程更加智能化和自动化。 总之,Power Scheduler通过建立批量大小和训练令牌数量无关的学习率调节机制,突破了传统训练参数设计的限制,是深度学习模型训练领域的一次重要进展。它不仅帮助研究者更有效地利用计算资源,还加速了大型语言模型的研发步伐。在人工智能高速发展的时代,类似Power Scheduler这样的创新工具,将持续推动技术边界,赋能更广泛的应用场景。
未来,随着更多实验验证和方法完善,期待这一调度策略能够被更多开源框架和商业平台集成,真正实现普惠与智能的训练体验。