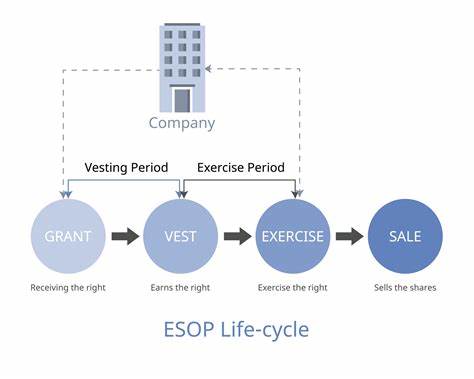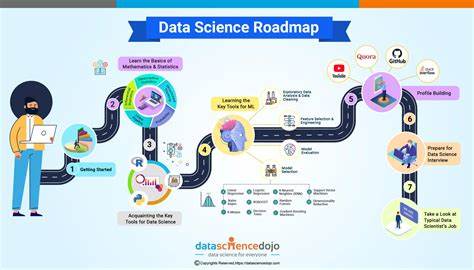
随着大数据时代的到来,数据科学成为推动企业与科技创新的重要力量。无论是初学者还是有一定经验的数据从业者,要想在这一领域获得成功,都需要一条清晰的学习路线。这篇文章将深入解析数据科学的核心组成部分,帮助你系统掌握必要的知识和技能,逐步构建起强大的数据科学能力。 数据科学的基础始于数学和统计学。理解概率论、统计推断和线性代数对分析数据至关重要,这些知识为后续的机器学习算法和数据模型奠定坚实的理论基础。数学能力的提升不仅有助于算法理解,也能让你更准确地评估数据模式和模型表现。
紧接着,编程能力是数据科学家必不可少的技能。Python 和 R 是数据科学领域中应用最广泛的编程语言。掌握这些工具能让你有效地进行数据清洗、数据可视化以及复杂的分析操作。通过实践项目,提升数据处理和脚本编写能力,将理论知识转化为实际成效。 数据获取与预处理则是数据科学过程中较为繁琐但极其关键的环节。展示从网页抓取、数据库查询到API调用等多种数据收集方式,同时强调数据清理、缺失值处理、异常值检测的必要性。
这些步骤决定模型训练的质量和最终结果的可靠性。 进入核心的机器学习领域,不论是监督学习中的回归与分类,还是无监督学习中的聚类和降维,都需要扎实的理论基础与实际经验。掌握常见的算法如决策树、支持向量机、神经网络,以及集成学习方法,有助于解决多样化的业务问题。 深度学习作为近年来的热点,更是推动了自然语言处理、图像识别等技术的飞跃。了解深度神经网络的结构与训练技巧,熟悉TensorFlow、PyTorch等深度学习框架,使你能应对复杂的非结构化数据和高维数据挑战。 此外,数据科学不仅是技术的堆砌,更是与业务理解紧密结合的职业。
培养洞察力,理解行业痛点和用户需求,是构建有效数据解决方案的关键因素。通过跨领域的交流与协作,提升项目管理和沟通能力,将技术成果成功转化为商业价值。 在数据可视化方面,学会运用工具如Tableau、Power BI以及Matplotlib和Seaborn等库,将复杂数据生动形象地展现出来,助力做出科学合理的决策。可视化不仅方便数据洞察,也极大地提升了与非技术人员的交流效率。 云计算和大数据平台为数据科学提供了强有力的技术支持。熟悉AWS、Google Cloud、Azure等云服务,掌握Hadoop、Spark等大数据技术,有助于处理海量数据,提升计算效率和模型部署能力,为业务带来快速响应与扩展性保障。
最后,数据科学发展迅速,持续学习和更新知识体系是赢得竞争优势的关键。关注最新的研究进展、工具和实践,积极参与开源项目和社区活动,能够拓展视野,增强实战经验,助力你的职业道路更加宽广。 迈出数据科学职业道路的第一步,遵循科学的学习规划,沉淀扎实的专业能力,将为你开启一片数据驱动的崭新天地。无论你是追求技术深度,还是希望在行业中发挥影响力,系统的路线图都能帮你理清方向,行动更有信心。