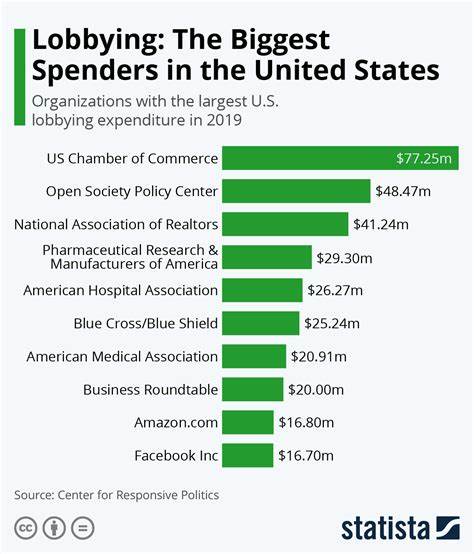
随着深度学习和GPU计算的普及,如何高效地将高层次的深度学习框架代码转化为底层高性能的GPU内核代码,成为计算机视觉、自然语言处理等领域发展的关键痛点。Qwen2.5-Coder-3B是一款基于大规模语言模型架构Qwen的代码专用模型,经过针对GPU内核生成的细致调优,特别适用于将PyTorch nn.Module代码自动转译为性能卓越的Triton内核代码。这一创新不仅极大简化了GPU代码的开发流程,也提升了代码的执行效率,成为AI开发者和系统优化工程师的新利器。Qwen2.5-Coder-3B模型基于Transformer架构,集成了RoPE(旋转位置编码)、SwiGLU激活函数与RMSNorm归一化技术,拥有超过30亿的参数及长达32768的上下文处理长度,使其能够理解并生成复杂代码结构。模型以PyTorch 2.5.0版本为基础,利用低秩适配(LoRA)技术进行精细调优,通过在GPUMODE/KernelBook数据集上训练,达到了98%以上的平均令牌精度和极低的训练损失,充分体现了其卓越的代码理解和生成能力。GPUMODE/KernelBook数据集是此次调优过程的核心资产,由18,162对PyTorch与对应Triton代码片段组成,通过torch.compile工具自动生成,包含大量真实项目中的类及函数映射关系,极大提高了模型对内核生成的泛化能力。
值得一提的是,使用该数据集的一个关键建议是保持PyTorch版本与训练阶段一致,确保生成代码的兼容性与稳定性。模型训练采用了NVIDIA H100 80GB显卡,使用AdamW优化器,配合bfloat16混合精度,在约98分钟内完成训练,彰显了高效的深度学习训练架构。使用Qwen2.5-Coder-3B进行Triton内核生成的过程简单而高效。用户只需将含有PyTorch `nn.Module`类定义的代码作为输入,按照预定义的结构化提示格式传递给模型即可,此时模型会自动输出对应的Triton代码。示例代码显示如何加载模型与分词器,构造提示语,并进行生成,最后解析输出获得高质量的GPU内核代码。Qwen2.5-Coder-3B最显著的优点之一是高质量的代码融合能力。
在传统的GPU编程中,开发者往往需要手动将多步张量操作融合成一个高性能内核,以尽可能减少内存访问和提升计算效率,而Qwen2.5-Coder-3B则能够自动识别PyTorch代码中操作间的依赖与优化点,生成融合度极高的Triton内核,从而以更低的计算资源消耗实现更快的推理速度。这种自动化程度不仅加速了研发流程,也降低了对GPU底层编程专家的依赖,极大地拓宽了深度学习模型开发者对GPU性能调优的应用范围。此外,Qwen2.5-Coder-3B的设计充分考虑了模型推理时的可扩展性与兼容性。它支持最大4096长度的序列输入,能够处理包括大型神经网络模块在内的复杂代码结构,适合多种规模的项目应用。从长远来看,Qwen2.5-Coder-3B以及类似自动代码生成模型的发展有望催生新一代GPU编程范式,实现AI驱动的GPU内核设计自动化。随着模型与数据集的不断更新和扩展,未来内核代码的优化水平将持续提升,使得更多前沿研究和工业应用能够受益于高性能计算的加速。
社区的活跃参与也为Qwen2.5-Coder-3B的改进与普及提供了坚实基础。用户不仅可以通过Hugging Face平台自由调用模型接口,还能参考相关开源代码进行自定义训练与微调,同时参与讨论推动技术进步。现阶段模型已广泛应用于科研实验和原型开发,特别是在高性能计算加速、深度学习模型优化和自动代码生成领域表现出巨大潜力。为进一步提升模型的实用性,官方提供了详尽的使用文档和示例代码,方便开发者快速上手。推荐安装PyTorch、Transformers、PEFT及Accelerate等依赖库,以确保环境兼容性和性能发掘。在实践中,实践者应注重输入代码的格式规范和提示层次,通过清晰的指令引导模型生成更准确、可执行的内核代码。
总体而言,Qwen2.5-Coder-3B在自动化PyTorch到Triton内核转换的技术路线中,展现了现代大规模语言模型针对代码生成任务的强大能力和广阔前景。其结合了深度学习与GPU底层编程的优势,推动了AI与高性能计算的深度融合,标志着GPU内核开发迈向自动化和智能化的新时代。未来,随着算力的不断提升及模型算法的优化,Qwen2.5-Coder-3B或将成为自动GPU内核生成领域的标杆,助力人工智能和计算科学的发展,为科研人员与工程师提供更高效、更智能的工具支持。