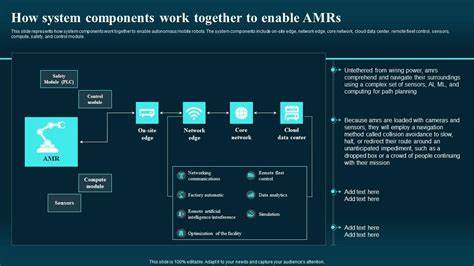
在现代编程语言中,闭包(Closure)作为一种强大且灵活的编程结构,已经成为提升代码复用性和维护性的关键技术。Hare作为一门注重性能与开发效率兼具的新兴语言,也同样支持闭包的概念。通过合理运用闭包,Hare开发者能够简化代码结构,增强函数式编程能力,并灵活管理变量作用域。本文将详细介绍Hare中的闭包原理、使用方式以及实际开发中的最佳实践,帮助程序员更好地掌握这一重要特性。 首先,理解闭包的核心在于理解其对变量访问范围的影响。在Hare中,闭包是一段能够捕获并“记住”其定义时环境中变量的匿名函数。
这意味着,即使外层函数已经执行完毕或作用域已经结束,闭包依旧能够访问和操作这些变量。这种行为使得闭包在实现数据封装、回调函数、延迟执行以及异步处理等场景中表现出极大的便利性。 Hare的闭包设计紧密结合其语法简洁和效率导向的特点。与其他常见的编程语言类似,Hare允许开发者通过函数嵌套定义闭包。函数内部定义的匿名函数可以直接访问外部函数的局部变量,而不会因外部作用域结束而失效。示例中定义的闭包函数可以在外部变量范围之外被调用,且持续影响捕获的变量,这种访问闭包变量的能力极大地丰富了编程模型。
使用闭包可以优化多种编程任务。例如,在构造事件处理器或监听器的时候,闭包能够保存事件产生时的上下文信息,确保后续处理逻辑能够正确关联事件源和状态。在数据流管理及变更观察中,闭包则提供了对私有变量的安全持久访问,避免全局变量污染,提高代码模块化水平。 此外,Hare的闭包在内存管理方面也经过了精心设计,避免了变量泄漏和资源浪费风险。变量的生命周期由闭包自动延伸,运用现代垃圾回收机制,高效清理不再被引用的资源。合理编写闭包不仅提升程序性能,也降低了内存使用的峰值,进而增强整体系统的响应速度。
然而,在运用闭包时也需要关注潜在的陷阱与误区。比如闭包对变量的捕获是引用类型,因此在循环中动态创建闭包时,若不正确处理变量作用域,可能导致所有闭包最终捕获同一变量,进而引发逻辑错误。对此,Hare提供了语法工具和编程规范以避免此类问题。开发者应当养成明确变量作用范围的习惯,避免闭包与外部状态产生不确定性干扰。 进一步而言,Hare支持将闭包作为函数参数传递和作为返回值返回,使得函数组合与高阶函数设计得以实现。借助闭包,可以构建高效的状态机、管道处理链和延迟计算结构,这在处理复杂业务逻辑、数据流转及异步操作时尤为重要。
得益于Hare语言特性,闭包的支持为编写灵活且可扩展的程序奠定了坚实的基础。 在实际项目中,应用闭包还可结合其他语言特性使用。例如,闭包与Hare的泛型结合能实现高度通用的函数组件。再如,与错误处理和并发控制结合,可以构建出更加健壮且具有弹性的服务逻辑。通过不断优化闭包的逻辑结构与调用模式,能够有效规避性能瓶颈,提高代码的执行效率和扩展潜力。 通过对Hare闭包机制的深入理解,开发者不仅能够写出更简洁优雅的代码,也能充分利用语言提供的灵活手段优化应用性能。
面对日益复杂的软件需求,掌握闭包技术将是提升个人或团队开发水平的重要步骤。建议开发者在熟悉基础语法后,多进行实际编码演练,从而深化对闭包各种细节的把控,结合项目需求灵活选用闭包解决方案,构筑高质量、高效率的软件体系。未来随着Hare语言生态的不断完善,闭包的应用将更加广泛,成为推动软件创新的中坚力量。 总结来说,Hare中的闭包不仅为代码提供了强有力的封装与数据隐藏能力,更在提高代码灵活性、可维护性方面发挥着重要作用。正确理解并运用闭包,能够让程序设计更具表达力和功能性,促进代码复用,优化程序结构。希望广大Hare程序员关注闭包的深层机制,不断探索其应用可能,共同推动高性能、高质量软件的实现。
。