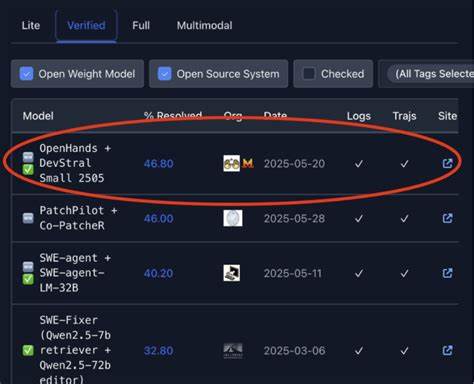
随着人工智能领域的迅猛发展,开源模型逐渐成为推动创新的重要力量。近年来,针对软件工程领域提出的SWE-Bench测试,成为评估AI模型代码理解与生成能力的重要基准。最新发布的状态显示开源模型在完整的500项SWE-Bench测试中取得了73.6%的准确率,这一成就标志着开源AI技术在软件开发辅助上的巨大进步。开源模型的优势在于透明性和可定制性,这使得研究者和开发者能够不断改进模型架构和训练数据,从而获得更高的性能。取得73.6%准确率的模型,通常结合了大规模预训练技术和针对软件工程特定任务的微调策略。预训练阶段,模型使用了涵盖多种编程语言和开发场景的海量代码库,增强了对语法结构及编程逻辑的理解能力,而微调阶段则侧重于解决实际开发场景中的核心难题,例如代码补全、错误检测和代码优化建议。
这一模型表现出的高准确率不仅反映了技术上的进步,也显著优化了软件开发流程。传统的编程工作往往耗时且容易出现人为错误,智能模型的介入使得编码效率大幅提升,同时帮助开发者降低调试和维护成本。其在SWE-Bench全套测试中表现出的优异性能,也预示着未来智能辅助开发工具将更为普及和强大。此外,开源社区的活跃使得模型能够快速迭代和分享最新成果,促进了技术的可持续发展和跨界融合。例如,一些模型采用了创新的自监督学习方法,有效提升了对代码语义和语境的理解,进一步推动了模型性能的提升。除技术因素外,数据质量和多样性同样关键。
高质量标注的代码数据集,为模型提供了准确的学习目标;多样化的代码示例则增强了模型的泛化能力,使其能够适应不同编程语言和风格。当前,开源模型在市面上的应用也越发广泛,部分智能编程工具已将此类模型集成于IDE(集成开发环境)中,助力开发者智能完成代码生成和问题分析。这不仅节约了大量开发时间,也促进了编程教育与实践的结合。然而,尽管取得了显著进步,开源模型依然面临一些挑战。如何进一步提升模型对复杂场景的理解能力,如何保证生成代码的安全性和可靠性,依旧是研究的重要方向。同时,伴随着开源模型规模的不断扩大,计算资源需求也日益增长,如何实现模型的高效部署和应用,也成为业界探讨的焦点。
未来,融合更丰富的多模态数据,如文档、图像及运行时日志,有望进一步增强模型的语义理解和推理能力,推动智能软件开发进入新的阶段。此外,跨学科合作和标准化建设也将是推动开源模型持续发展的关键。总的来看,开源模型在SWE-Bench中取得的73.6%准确率,不仅展示了当前技术的高度成熟,也为软件工程领域带来了革命性的可能。不断优化的模型架构、精细化的训练流程以及社区的协同创新,共同促进了智能编程工具的普及与升级。未来工作将聚焦于提升复杂任务处理能力和推动技术普惠,助力全球开发者实现更加高效和创新的编程体验。 。