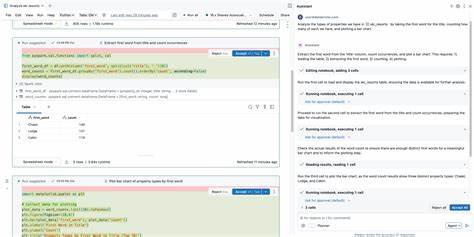
随着人工智能与大数据技术的飞速发展,数据科学已成为推动企业创新与变革的关键力量。然而,传统的数据分析与机器学习流程常常耗时费力,涉及复杂的编码、调试和模型训练环节。Databricks作为领先的云端数据分析平台,其最新推出的助手 - - 数据科学代理(Data Science Agent)正引领数据科学工作方式的革新,实现了从数据探索到结果输出的极速体验,极大地提升了工作效率和成果质量。 数据科学代理是Databricks助手的新一代智能工具,旨在成为数据科学家和分析师的自主合作伙伴。它不仅能够理解用户的自然语言指令,还能自动生成并执行SQL或Python代码,完成数据探索、模型训练、错误诊断和结果解读等复杂任务。值得注意的是,该代理深度整合了Databricks独有的Unity Catalog统一数据目录,确保了所有操作均在安全合规的环境下进行,有效保障了数据治理和访问权限的规范管理。
这一代理的核心优势在于其强大的自主执行能力。传统上,数据科学项目往往需要专家逐步编码和调整,通过反复试错才能完成分析和建模。而数据科学代理只需一个简洁的自然语言提示,便能迅速完成外延丰富的数据探索,识别潜在模式并自动生成有价值的见解。比如,用户只需输入"对@table执行探索性数据分析,找出有趣的趋势",代理便会针对指定数据集展开细致分析,生成代码、图表,甚至提出后续优化建议。 在机器学习方面,代理同样展现出卓越能力。它能够利用Databricks内置的MLflow平台,执行端到端的模型训练和评估流程。
用户可指示代理构建预测模型、选择算法、调整超参数甚至进行模型比较,所有操作几乎无需人工干预,大大缩短了项目的研发周期。此外,代理还能自动修正代码中的错误,配合"诊断错误"按钮,实现多轮迭代修改,确保工作顺利推进。 数据搜索与发现也是数据科学代理的一大亮点。借助Unity Catalog的元数据管理,代理可以根据用户对数据列名称或数据类型的描述,快速定位相关数据资源。尤其当表和列配备详细注释时,搜索效果更加精准,帮助用户在庞大的数据湖中高效找到所需资产,避免了传统人工搜寻的低效和遗漏风险。 值得关注的是,数据科学代理蕴含了严密的安全与合规设计。
它不仅在执行代码前请求用户授权,还内置多重防护机制,防止诸如误删表等风险操作。这种交互式控制让用户在享受自动化便利的同时,始终保持对数据资产的全面掌控,避免潜在的安全隐患。 Databricks为满足更复杂场景也提供了代理的规划功能(Planner)。用户可以启用规划模式,让代理先制定详细的执行步骤计划,并通过对话澄清需求,再有条理地分步实施任务。这对于需要多阶段分析或建立完整机器学习流水线尤为重要。代理能够协调数据清洗、特征工程、模型训练及验证环节,使工作流程系统化且透明,提升项目整体管理水平。
在实际应用中,数据科学代理极大地释放了数据团队的生产力。它适用于零售销售预测、客户流失分析、金融风险评估等多种行业场景。企业不仅能减少人为错误和重复性劳动,还能利用更短的时间周期获取深入洞察,为决策层提供有力支持。代理的快速响应还使数据科学家能将更多时间投入于创新和策略制定,而非琐碎的技术细节。 展望未来,Databricks计划进一步强化数据科学代理的智能化水平和场景适应能力。通过引入多云数据平台整合(MCP)、提升上下文记忆和指令管理能力,代理将能够理解更丰富的业务背景,实现更精准和个性化的服务。
此外,搜索功能也将不断优化,帮助用户更快捷地发现所需数据和代码资源,实现真正的数据资产智慧化管理。 随着智能代理技术的持续演进,数据科学代理不仅是命令执行的助手,更将逐步成长为企业数字化转型的助推器。它标志着人机协作的新阶段 - - 不仅能听懂指令,更能自主规划、执行并提供高质量反馈。对企业而言,这意味着极大提升数据科学的效率和可信度,更快实现从数据到价值的转化。 总结来看,Databricks数据科学代理以其高效、智能、安全的设计理念,推动数据科学从繁琐的编码操作迈向高度自动化和智能化。它为数据分析师和科学家释放了大量时间和精力,使他们能够专注于洞察和创新。
作为数据驱动的未来的重要工具,数据科学代理必将在各行业数据策略中发挥核心作用,帮助企业快速响应市场变化,赢得竞争优势。如今,借助Databricks助手的代理模式,数据探索与成果输出只需几分钟,真正实现了从问题到答案的极速跨越。 。