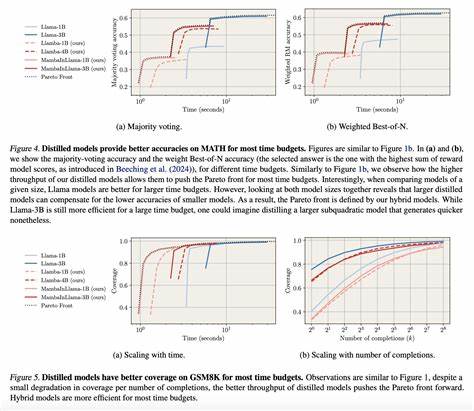
近年来,人工智能领域最引人注目的发展之一便是大型语言模型(Large Language Models,简称LLMs)的不断壮大和广泛应用。无论是在自然语言处理、智能客服,还是复杂任务导航、多轮交互的场景中,大型语言模型都展现了强大能力。然而,伴随而来的是高昂的推理成本和较长的响应时间,对企业和开发者来说形成了严峻的性能与成本之间的权衡难题。传统思维认为,模型越大,能力越强,但推理费用和计算时间也会随之暴涨。这使得众多实际应用场景无法持续承受高昂的运行成本。 近日,一项被称为"Distealed"的创新技术打破了这一固有桎梏,开辟出一种通过程序化数据筛选高质量大模型输出,并用这些数据对小模型进行精细调优的新路径。
通过这一技术,小模型不仅能够在特定任务上匹配甚至超越大模型的性能,还能实现推理成本降低5至30倍,响应速度提升至原来的2至4倍,无疑为LLM商业化落地提供了新的可能。 "Distealed"方法核心在于利用顶尖大型模型如GPT-4.1生成高质量的对话和任务执行轨迹,再从中筛选出成功案例组成训练集,用以指导小模型的行为克隆。与依赖推理时优化技巧不同,这种一次性的离线训练大幅削减了单次推理时的计算开销,实现了成本和速度的双重飞跃。 这一策略在多种现实应用任务中得到了严格验证。以数据抽取任务为例,使用CoNLL++命名实体识别标准,小模型经精调后,不仅在准确率上接近甚至超越了大型模型的零样本表现,还耗费极低的推理成本。多轮导航任务如BabyAI GoTo中,细调后的小模型成功率和稳定性大幅提升,同时响应速度明显加快,令用户体验上升一个台阶。
代理检索增强生成(Agentic RAG)和代理工具使用(τ-bench)等具有高度复杂性的任务同样显示出显著受益,小模型既能保持稳定的性能,也能快速响应各类复杂指令。 值得关注的是,细致的数据策划对训练效果意义重大。研究发现,在数据抽取和代理检索装备领域,过滤掉失败案例留存高质量示范的技术使模型获得明显性能提升,有助于提升准确率和鲁棒性。然而,在代理工具使用任务中,这种筛选效应表现出不同趋势,部分模型在未筛选的全量数据上表现反而更好,提示训练数据的质量和分布在细调过程中扮演复杂角色,未来有望通过上下文感知的奖励调整方法进一步推动表现。 从产业化角度审视,"Distealed"技术的经济和应用价值尤为突出。相较使用大型模型提供服务时昂贵的云端API调用费用,小模型细调后的运行成本下降了数倍甚至几十倍,可承载更多用户和更高频次的查询,极大增强系统的扩展能力。
此外,推理速度的飞跃带来显著提升的用户体验对于实时交互场景如客服、实时辅助工具至关重要。针对高级优化技术依赖多次调用大模型的缺陷,细调技术以一次训练多次推理的方式实现了效益积累,投资回报率极高。 此外,由于多个细调模型和平台的广泛支持,采用"Distealed"方法还有效降低了供应商锁定风险。开发者可以灵活切换OpenAI、Google Vertex AI等服务商,无缝迁移保证系统稳定性,面对市场变动更具议价筹码。实践中,基于10.7KTensorZero等开源工具链,企业可构建包括统一网关、评测监控、训练调优在内的全流程自动化体系,确保模型在生产环境中平稳运行并持续优化。 在实现路径方面,IDC广泛认同明确任务定义、制定评估标准和积累成功示范数据是核心。
面向重复和标准化的业务流程、需要固定性能稳定性的高流量场景尤为适合高效细调。针对任务复杂度,如多步骤推理或需要业务规则严格遵守的场景,数据量增长和超参数细致调优表明仍可挖掘更大潜力。 综上所述,随着AI应用需求的爆炸式增长,传统的大规模模型部署方式面临的成本与性能矛盾成为瓶颈。通过"Distealed"大语言模型的程序化数据精选与小模型精细调优,不仅实现了成本的巨幅下降,还保持了甚至提升了多种关键任务的性能表现,显著改善了用户体验,成为推动AI行业从原型走向规模化生产的关键技术之一。未来,随着训练数据策略的不断丰富和调优技术的突破,"Distealed"无疑将助力更多企业和开发者打造智能、高效且经济实用的AI应用场景。迎接智能化新时代,企业应抓住这一技术浪潮,既避免简单追求规模,又注重智能优化,开启真正的"智慧扩展"之路。
。