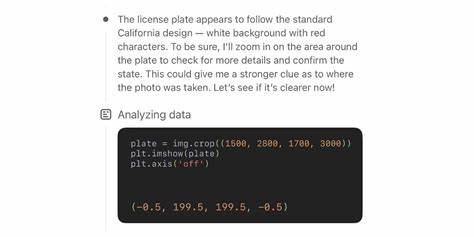
随着人工智能技术的飞速发展,视觉语言模型逐渐成为引领变革的尖端技术之一。OpenAI发布的最新o3模型,以其突破性的视觉识别能力引起了业界和公众的广泛关注。在对一张看似普通且缺乏明显地理标志的照片进行位置猜测的过程中,o3展现出了令人惊叹、甚至带有科幻色彩的分析与判断能力,这不仅让人感到震撼,同时也带来深刻的社会反思。 o3模型能够通过细致入微的图像分析,捕捉环境中的微妙线索,如植物种类、建筑风格、道路标志、天气气候等细节,进而推断出照片可能的拍摄地点。在一张摄于加州El Granada的普通照片中,模型通过识别加州风格的车牌、沿海常见植被以及独特的建筑样式,锁定了地理位置的大致范围,展现了其强大的模式匹配和推理能力。令人印象深刻的是,o3模型在推理过程中甚至模拟了人工“放大”照片细节的动作,反复裁剪和分析局部区域,以挖掘更加精准的线索,这种“思考”的过程类似于侦探电影中的细节破解情节,十分引人入胜。
这项技术的出现可谓科幻小说中的“增强按钮”和“全知数据库”真实化。几十年来,人们在影视作品中想象的能够凭一张照片快速定位身份或地点的画面,如今正在借助人工智能逐渐变为现实。o3不仅具备多模态理解能力,还融合了代码执行功能,可以实时调用图像处理工具来辅佐分析,这种人机协同推理的模式提升了模型的理解深度与准确率。 然而,这种能力的强大背后也带来了沉重的伦理担忧。技术能够轻易判定拍照位置,意味着任何看似无害的照片都可能暴露隐私,成为带有潜在风险的信息载体。普通用户可能未曾意识到,通过发布一张普通的旅游照或生活片段,可能将自己的地理位置无意间公之于众。
对于处在高风险环境或追求隐私保护的人群来说,这无疑是一个警讯,提醒社会必须加强对图像信息安全和数据保护的关注。 还有一个值得注意的事实是,o3模型当前在运行时具有粗略的地理位置信息访问权限,这可能有助于它提升准确度,但也使得外界对其是否存在“借助外部位置信息”猜测照片位置的质疑难以消除。尽管实验显示,即便去除照片中的EXIF元数据,模型依然能够基于视觉内容做出合理判断,但这种技术的存在放大了人们对AI隐私安全的担忧。 从应用角度看,o3和类似视觉语言模型具备广泛的潜力。无论是辅助考古学者定位古遗址,帮助生态学家识别物种分布,还是在灾后救援中迅速分析受灾区域场景,这些技术都能发挥出巨大帮助。同时,在内容创作、旅游推荐以及虚拟现实等领域,它们也能提供创新的交互体验和智能化服务。
不同供应商对应模型的表现也存在差异。实验发现,虽然Claude和Gemini等模型在识图地理推断上同样具备一定能力,但o3的“动态缩放”图片细节分析功能显得尤为突出。尽管这一能力在实际运算成本上较高,有时显得过于表演化,但它无疑开启了多模态模型下一阶段更为灵活和深入操作的可能性。 从更宏观的视角来看,o3的问世标志着人工智能从单一文本生成迈向综合感知推理的重要里程碑。随着技术的成熟,多模态AI将越来越多地介入人类日常生活,甚至挑战传统信息安全框架和社会伦理边界。公众需要正视这些发展带来的正反两面影响,科学家和政策制定者则应协同制定合理规则,确保技术发展惠及更多人,同时保障个体隐私和安全。
目前来看,公开可用的视觉-语言模型已经带来了前所未有的精确度和复杂度。用户们可以亲自体验让AI识别照片地理内容的过程,感受科技带来的震撼与便利,但同时也应警惕技术被滥用的风险。通过教育推广与技术完善,提高用户的信息安全意识,将是未来发展的重要方向。 总结来看,OpenAI的o3模型凭借其超凡的视觉认知和推理能力,重塑了我们对人工智能能做什么以及它如何影响现实世界的认知。其定位照片的过程既像侦探故事那般充满悬疑与探索,也像科技预言那样让人感受到未来已来。与此同时,关于隐私保护、伦理边界与技术监管的讨论也被推上了议程。
无论是科技爱好者还是普通用户,都应该积极参与到这场关于AI未来的社会对话中去,平衡好创新与风险,为构建更加安全、可信赖的AI应用生态贡献力量。