近年来,随着人工智能技术的飞速发展,大型语言模型(LLM)在自然语言处理领域展现出巨大的潜力和应用价值。众多行业从文本生成、翻译、内容审核到智能问答等都依赖于这些模型。作为2025年表现卓越的开源模型之一,Qwen3凭借其优异的性能和开源友好的许可协议,成为广大开发者与研究者关注的焦点。本文将从基础概念入手,逐步剖析Qwen3模型的架构亮点和实现细节,帮助读者全面理解并具备动手复现该模型的能力,从而在开源LLM领域占据先机。 Qwen3模型最初于2025年五月发布,并于七月进行了重要的更新。它以Apache License v2.0开源许可发布,无任何附加使用限制,这一点极大促进了模型的普及和商业应用。
相比一些其他开源大型语言模型在使用上设限,Qwen3几乎为开发者提供了最大的自由度。此外,Qwen3系列涵盖了从0.6B参数的轻量级密集模型到480B参数的专家混合模型,能够满足各种规模的算力资源和多样化应用需求。 在性能方面,Qwen3同样表现出色。235B参数的Instruct版本在著名的LMArena排行榜中排名第八,与私有模型Claude Opus 4持平。仅有两款更大规模的开源模型DeepSeek 3.1和Kimi K2超越它,分别是其三倍和四倍的参数规模。更令人瞩目的是,2025年九月发布的1万亿参数级别的"max"版本,虽然目前仍为闭源,但已在所有主流基准测试中击败了Kimi K2和DeepSeek 3.1,展现出令人振奋的未来发展潜力。
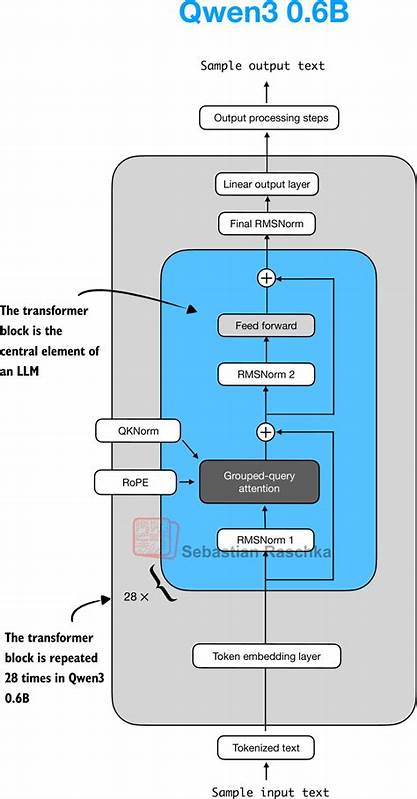
在架构设计方面,Qwen3融合了当前先进的技术理念和创新的模块设计。其核心架构采用Transformer变体,结合了Mixture-of-Experts(MoE)策略,有效提升模型在海量参数下的计算效率和表达能力。MoE通过专家网络选择机制,只激活部分子网络参与推理,减少了计算资源的浪费,同时保持语义理解的深度和多样性。Qwen3的这一架构设计使得它能够灵活适应不同场景的需求,既能运行轻量级模型进行快速部署,也能利用大型MoE模型处理高度复杂且开放领域的任务。 除了模型架构,Qwen3在训练方法上也进行了优化。为了确保训练效率和模型泛化能力,研究团队应用了混合精度训练、分布式训练策略,并采用了精心设计的数据增强和指令调优(Instruct tuning),提升模型对指令的准确响应能力和上下文理解水平。
指令调优尤其使得Qwen3在多样化的任务中表现更加自然和可靠,符合实际应用中对智能交互的严苛要求。 随着技术的成熟,如何从零实现Qwen3成为众多AI开发者和研究者的重要课题。通过纯PyTorch框架的实战复现,开发者不仅能深入理解模型的每一个构建块,还能探索和扩展相关模块以适应自己特定需求。PyTorch本身以灵活易用著称,支持动态计算图,这对调试复杂模型和实现创新变种极为有利。 实现过程中,关键模块如多头自注意力机制、前馈网络、层归一化及专家路由机制需要逐步构建。多头注意力通过多个平行的注意力头捕捉不同语义层次的信息,实现对输入序列的深度编码。
前馈网络则负责非线性变换,增强模型表达力。专家路由机制则依据输入特征智能分配给不同专家子网络进行处理,极大提升模型参数的利用效率。 为了增强模型的稳定性,添加残差连接和层归一化也是关键步骤。这些技术保证了深层网络训练时信号的有效流动,避免梯度消失或爆炸情况发生。进一步地,合理设置学习率调度和优化器(如AdamW)的细节,也是训练高质量Qwen3模型不可缺少的一环。 数据准备也是复现过程中的重要环节。
高质量的训练语料和多样化的指令数据直接决定模型性能。通常需要对文本数据进行清洗、分词和向量化,构建合适的词汇表和嵌入层,也可能结合大规模的预训练语料与针对特定任务的微调数据。 完成模型实现和训练后,评估是验证模型效果的关键步骤。LMArena等标准基准提供了多维度评价指标,包括文本理解、生成质量、指令执行准确性等。通过细致的测试,能够发现模型潜在的优势和不足,指导后续的改进。 Qwen3的开源特点不仅降低了大型语言模型的门槛,也为人工智能产业的创新提供了丰富资源。
无论是初创企业、中小型研发团队,抑或高校实验室,都能借助Qwen3打造定制化AI解决方案,推动智能交互、内容生成和知识检索等领域的发展。 未来,随着硬件性能提升和算法优化,基于Qwen3架构的变体可能继续刷新开源模型的性能极限。融合多模态数据、增强推理能力和提升模型安全性等方向,也将成为研究热点。通过社区协作与持续创新,Qwen3有望成为开源AI生态系统的重要基石,引领大型语言模型的下一个浪潮。 总之,Qwen3以其先进的设计理念、优异的性能表现和友好的开源许可,成为2025年不可忽视的产业明星。通过深入学习其原理并实践实现,开发者不仅提升了技术水平,更为构建智能未来奠定了坚实基础。
期待越来越多的技术爱好者加入到Qwen3生态中,共同探索开源大型语言模型的无限可能。 。