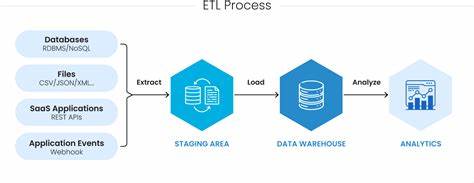
随着电商行业的飞速发展,产品数据的精准采集和高效整合成为了企业获取竞争优势的关键。许多商家希望能够自动从多个品牌官网和电商平台抓取产品信息,进行统一管理,快速响应市场变化。ETL(Extract,Transform,Load)系统因此应运而生,成为数据自动化采集、处理和加载的利器。尤其是在使用Shopify等主流电商平台的背景下,如何构建稳定、灵活且可扩展的ETL系统实现数据自动采集上线,成为众多技术团队关注的焦点。本文深入探讨一套基于Python和Selenium的开源ETL解决方案,详解其架构设计、核心模块和应用场景,助力读者打造专业高效的数据爬取及集成平台。构建该ETL系统的核心目的是针对市场上各种品牌补充剂产品,实现从官网到数据仓库再到电商平台的全面数据闭环管理。
系统通过模块化设计分别负责数据抽取、转换和加载,确保整个流程高效且可维护。首先,在数据抽取层面,项目利用Selenium实现针对不同网站的动态网页爬取和自动化操作,能够适配JavaScript渲染的界面,克服静态爬取难题。抽取模块以服务化理念构建,方便通过配置扩展支持更多网站源。接下来,数据转换层将初步抓取的原始数据进行格式化与清洗,标准化产品名称、规格、价格和描述内容,同时集成自然语言处理技术,自动丰富产品文案,提升电商展示效果。数据转换还包含合理分类规则,基于预定义的词表与集合体系,帮助精准划分产品类别和风味属性,方便后续检索与分析。最后,数据加载模块专门负责将处理后的产品信息安全高效地上传至Shopify平台。
利用Shopify官方API,系统支持商品创建、变更同步与库存更新等操作,保障线上店铺数据实时一致。该模块可灵活配置对应不同店铺,满足多品牌多渠道的复杂业务需求。在技术栈层面,该项目以Python为主语言,依托丰富的第三方库实现快速开发。Selenium负责浏览器自动化,支持Chrome等主流浏览器无缝运行,提升爬取稳定性。底层架构遵循ETL经典设计模式,代码目录清晰划分抽取、转换、加载及工具模块,便于开发维护和功能迭代。项目还包含针对定时任务的调度机制,结合轻量级脚本管理,提高自动化运行的灵活度和安全性。
除了技术细节之外,这套解决方案还注重可扩展性和适应性。各个模块之间低耦合、高内聚,支持后续轻松集成更多数据源或电商平台。同时,采用配置驱动的开发方式,无需大量代码改动即可调整采集逻辑或API参数,极大降低了二次开发成本。对于电商运营人员而言,这意味着能够快速响应市场变化,持续更新产品信息,提升店铺竞争力。值得一提的是,数据质量管理被系统重点关注。专门设计了数据完整性验证、格式异常检测和日志追踪等机制,确保采集流程稳定运行,避免错误数据影响业务。
通过多维度的质量控制,最终输出高可信度的产品信息,增强决策支持能力。在实际应用场景中,这种ETL系统广泛适用于品牌经销商、电商代运营及数据分析团队。它不仅能够实现全自动化采集节省人力成本,还能打通数据孤岛,形成统一的产品信息中台。借助系统灵活的插件化设计,团队能够专注业务优化,而非繁琐的数据整合工作。此外,系统对多网站多规则的支持能力也为未来业务多渠道拓展铺垫基础。面对快速变化的网页结构和 API 规则,开发者只需调整配置文件或新增采集模块,系统即可快速适配,无缝完成数据更新。
展望ETL技术在电商领域的应用趋势,结合大数据和人工智能,未来系统或将引入智能爬虫调度、自动异常检测与智能内容生成等功能,进一步提升自动化和智能化程度。优化网页解析策略和模型训练,实现更精准的产品属性提取,打造全流程智能数据采集解决方案。综合来看,当前这套基于Python和Selenium的ETL系统,有效满足了从多网站抓取产品信息到Shopify电商平台展现的全链路需求。它不仅极大简化了数据运营流程,也帮助电商企业提升数据资产价值和市场响应速度。对于希望快速搭建自动采集平台的技术团队和运营团队而言,深入理解其架构设计与核心模块,实现模块定制与优化,必将助力业务迈向智能化数据驱动未来。随着电商业务规模不断扩大,数据流通与应用的复杂度增加,高效、灵活的ETL系统将持续发挥无可替代的重要作用。
选择合适的工具与技术栈,构建专业的数据采集与管理平台,让自动化成为企业的长期竞争优势。