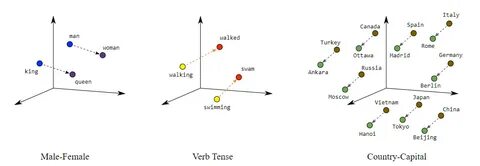
随着人工智能技术的飞速发展,尤其是大型语言模型(LLM)的广泛应用,理解这些模型内部的复杂工作机理变得尤为重要。大型语言模型通过生成高维度的嵌入向量来编码丰富的语义和句法信息,这些高维空间蕴藏着诸多潜在的语言规律与知识。然而,由于嵌入空间的维度极高且结构复杂,其内部的拓扑关系和语义编码特征难以直观解释和分析。Explainable Mapper作为一种创新的探索框架,结合了拓扑数据分析与扰动解释技术,为研究者提供了有效的方法来揭示和理解LLM嵌入空间的内部结构与语言属性。大型语言模型的嵌入空间是多维、非线性的复杂向量空间,其中每一个嵌入向量都代表了一个单词、短语或概念的语义表示。传统的分析手段往往受限于维度灾难和可视化的障碍,这使得对这些嵌入的深入理解充满挑战。
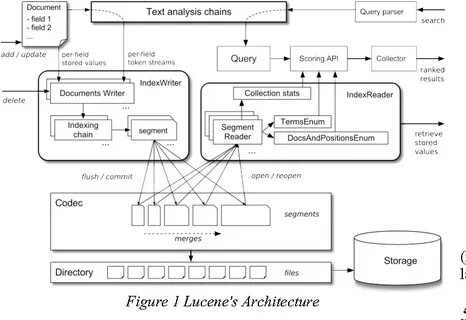
Mapper算法通过构建图形化的拓扑摘要,能够将嵌入数据转化为可解释的结构表示。具体来说,Mapper图由若干顶点(节点)组成,每一个节点表示嵌入空间中的一个拓扑邻域或聚类,同时节点之间的边表示这些邻域之间的重叠关系。这种方式不仅揭示了嵌入空间的整体形态,也帮助识别语义和句法上的模式和区分。不过,单独借助Mapper图的可视化,人类分析者仍需花费大量时间和精力来理解和注释每个节点或路径背后的语言学含义。在此背景下,Explainable Mapper提出了半自动化的注释框架,利用先进的扰动技术结合基于LLM的智能代理来辅助分析。扰动方法通过在输入嵌入向量或文本上引入细微变化,观察这些变化对结果的影响,从而揭示嵌入的敏感性和特征稳定性。
这种机制类似于在黑盒模型中做局部解释,揭示具体维度或局部区域对语言属性编码的重要性。Explainable Mapper设计了两类定制化的LLM代理,分别执行解释和验证任务。解释代理负责利用扰动技术对Mapper图中的元素如节点、边、路径等进行自动感知和语言学属性分析,辅助人类探索者理解其内涵。验证代理则负责对解释代理提出的解释进行稳健性检测,确保结果的可信度和一致性。这样一来,研究者能够高效地标注嵌入空间的结构,同时获得经过技术验证的解释结果。为提升用户体验,Explainable Mapper被集成到了一个可视分析平台中。
该平台不仅支持Mapper图的交互式浏览,也允许用户灵活调整扰动参数,实时观察解释代理的反馈,极大地丰富了对嵌入空间的认知。值得注意的是,该框架验证了此前基于BERT模型的研究成果,成功复制了多个层次嵌入向量的语言属性发现,同时在此基础上发掘出更多细粒度的拓扑邻域语言规律。这不仅深化了学术界对语言模型内部复杂结构的理解,也为后续模型设计和应用提供了新思路。Explainable Mapper在提升LLM嵌入空间可解释性方面意义深远。首先,它弥合了传统拓扑数据分析与现代扰动解释技术之间的空白,使得高维复杂数据的语言学解释更为准确和系统。其次,通过半自动化分析,降低了专家对大量人工注释的依赖,提高了研究的规模效能和可重复性。
最后,该框架为未来机器学习模型的透明度和可信度建设提供了范例,响应了AI伦理中对于可解释性的迫切需求。随着大型语言模型在自然语言处理、对话系统、文本生成等领域的不断扩展,Explainable Mapper所代表的这种深入而系统的嵌入空间探究方法,将成为理解和优化模型性能的重要利器。未来,结合更多样化的扰动策略和跨模态数据,Explainable Mapper有望实现更全面的解释能力,推动人工智能向更加智能和可信的方向演进。综上所述,Explainable Mapper是一项开创性的研究工具,利用拓扑摘要图的结构化表示和基于扰动的解释验证机制,显著推动了大型语言模型嵌入空间的可解释性研究。这不仅助力研究人员揭示深层语义和语法关系,也加深了人们对复杂语言模型内部逻辑的认知,为自然语言处理领域带来了新的研究视角和实践指南。