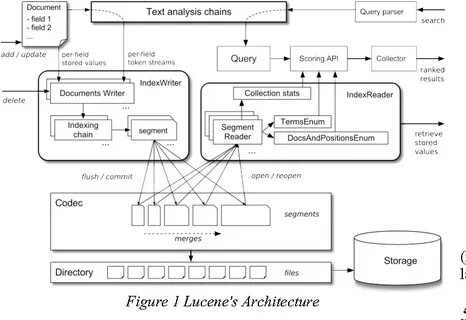
随着大数据与信息爆炸时代的到来,文本数据的检索与处理变得尤为重要。Apache Lucene作为一款功能强大的开源全文检索库,其核心组件之一——分析器(analyzer)发挥着至关重要的作用。分析器不仅直接决定了搜索的相关性和准确度,也影响到数据预处理效率与系统响应速度。理解并善用Lucene分析器是每位开发者构建高效搜索平台的必备技能。Apache Lucene分析器的核心功能是将输入的文本转换为一系列可索引的词元(tokens),这个过程包括分词、标准化、过滤等多个环节。通过这些步骤,原始文本内容被拆解成结构化的信息单元,方便后续的索引和搜索查询处理。
Lucene分析器主要包含三个关键组件:分词器(tokenizer)、过滤器(token filter)和字符过滤器(char filter)。分词器负责将文本拆分成基本词元,过滤器用于对初步的词元进行处理,比如小写转换、去除停用词、同义词扩展等,字符过滤器则可以对文本进行预处理,例如HTML标签清理、特殊符号替换等。使用Lucene分析器的最大优势在于其高度的可配置性和扩展性。根据具体需求,开发者可以自由组合不同的分词器和过滤器,甚至自定义实现复杂的文本处理逻辑。无论是构建多语言支持的搜索引擎,还是开发针对特定领域的专业文本分析工具,Lucene分析器都能提供灵活且高效的解决方案。以中文文本处理为例,由于中文缺乏明显的词语边界,准确的分词技术尤为重要。
Lucene通过集成IKAnalyzer、SmartChineseAnalyzer等第三方分词器,有效提升中文文本的分词质量,进而增强检索的精准性。此外,过滤器还可用于同义词处理、词干还原等复杂操作,从而增强搜索的泛化能力和容错率。在实际应用中,Lucene分析器的性能表现同样出色。其设计遵循流水线处理模式,支持多线程并发处理,有效利用现代多核CPU资源。这保证了在大规模文本索引和查询环境下,系统依然保持良好的响应速度和稳定性。同时,Lucene社区活跃,不断迭代优化分析器组件,涵盖更多语言及行业应用场景,满足不断变化的需求。
Apache Lucene分析器不仅是搜索引擎的核心,更是数据挖掘、自然语言处理、智能推荐等领域的基础组件。通过对文本实行分层次、模块化的处理,不仅提升了信息检索的效率,也增强了语义理解的能力,助力系统实现更智能的决策支持。对于刚接触Lucene的开发者,建议先从理解标准分析器开始,熟悉其工作流程及关键接口,逐步尝试添加不同的过滤器并观察效果变化。利用Lucene提供的丰富文档和示例代码,可以快速构建适合自身业务的分析器配置,减少开发周期,提高项目成功率。同时结合云计算和大数据技术,将Lucene分析器集成进分布式系统中,可以实现海量数据的实时处理与高效检索,满足现代企业对数据应用的苛刻需求。总的来说,Apache Lucene分析器凭借其灵活性、可扩展性和卓越性能,成为文本处理领域的重要利器。
深入掌握其原理和使用技巧,不仅能够打造强大、可靠的搜索引擎,更能在自然语言处理、内容推荐等多个方向开拓新的应用场景。未来随着人工智能的发展,Lucene分析器也将不断演进,助力开发者创造更加智能、高效的信息处理平台。