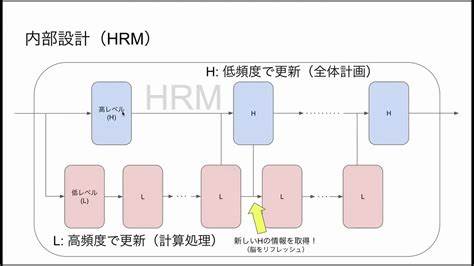
随着人工智能技术的快速发展,如何在复杂任务中实现高效而准确的推理,成为学术界和工业界关注的焦点。层次推理模型(Hierarchical Reasoning Model,简称HRM)作为一种创新性的架构,借鉴了人脑多时尺度处理的原理,通过将推理过程分解为不同频率的模块协同工作,实现了在路径规划等任务中卓越的性能表现。HRM最初由Guan Wang等人提出,之后被多个研究者在细节和实现上进行了改进与扩展,形成了适合教育和实际应用的版本。本文将重点介绍HRM的核心设计思想、实现方式及性能评估,尤其是针对其架构组成部分的重要性所做的消融研究。HRM的架构灵感来源于人类大脑处理信息的层次性和多时间尺度特征。在模型中,两个具有自注意力机制的循环模块以不同频率运行。
H模块担负抽象规划的职责,运行速度较慢,负责处理宏观层面的推理;L模块则速度较快,更专注于具体的低级计算。两者的协同能够在潜在空间内完成有效推理,提升模型对复杂任务的理解和执行能力。具体应用案例包括路径寻找任务:在一个N×N尺寸的棋盘上,棋盘上存在各种障碍,模型需要找到从起点到终点的最短可行路径。该任务既考验模型的空间识别能力,也挑战争策略的推理水平。模型推断过程的动画展示了HRM逐步细化路径的能力,明显体现出分层推理的优势。实现HRM需要依赖PyTorch等深度学习框架,整体代码结构包括输入嵌入、两个推理模块(对应H和L),以及线性映射层。
其中,输入嵌入部分将棋盘中的每个单元格信息转换为高维向量表示,随后由H和L模块通过多层堆叠的HRMBlock进行推理。HRMBlock独具特色地包含了两个子层:一种是带有残差连接和RMSNorm归一化的缩放点积自注意力机制(SDPAttention),另一种则是基于SwiGLU激活函数的多层感知机(MLP)。这使得模型不仅捕获了序列中的时序依赖,还能有效地进行非线性变换,增强表示能力。此外,模型对位置编码进行了灵活设计,可以同时采用旋转位置编码(RoPE)和学习型绝对位置编码,提高了模型对位置信息的敏感性。与原始工作相比,该版本做出了一些简化和调整,比如取消Q-learning与自动计算终止(ACT)机制,采用标准初始化方式,及使用nn.RMSNorm替代其他归一化方式。这些变化在不损害模型性能的情况下,提升了代码的可读性和易用性。
为了验证模型设计的合理性及各模块的贡献,研究者进行了多项消融实验,尤其聚焦于架构中双模块设计的作用和训练中"段数"对性能的影响。消融实验以20×20大小棋盘,障碍概率为0.3为实验场景,在训练集上进行了40个周期的训练,并对验证集进行了评估。实验中比较了多种结构变体,包括仅使用H模块的单模块设计(分别以带和不带BPTT的方式训练)以及完整H/L双模块设计。为了公平比较,各变体均调整参数规模至相当数量级。实验结果显示,训练时的段数对最终表现影响最大。段数越多,模型获得的准确率和推断上的精细调整能力都大幅提升。
相较之下,结构类型(单模块还是双模块)对最终性能影响较小,带来的差异远不及训练策略上的调整显著。加大处理的周期数能够提高整体准确率,但并未显著增强推断时模型对结果细化的能力。值得关注的是,H/L架构在不使用反向传播截断(detached)训练时,依然能达到较好的性能水平。这意味着模型在保持推理能力的同时,可能降低了训练成本,具有潜在的应用价值。综合消融实验的发现,可以看出HRM的关键性能驱动力更多地来自于"外层循环"的迭代细化,而非单纯的层次结构划分。这与ARC Prize团队此前的分析结论相呼应,强调了模型持续推理与自我纠正的重要性。
训练过程中,较多的训练段数赋予模型能够逐步打磨答案的能力,随着推断阶段额外的迭代推理步骤,准确率进一步提升。从视觉呈现上看,模型在早期推理步骤中做出较为粗略的路径规划,随着时间推移逐步补充和修正细节,直至最终得到完整且准确的路径。这种逐步细化策略不仅符合认知科学中分层控制的理论,也为构建具备主动规划能力的智能系统提供了重要启示。总结来看,层次推理模型作为一种将生物认知机制与现代深度学习相结合的尝试,有效地促进了复杂空间任务中的推理能力。其双时序模块架构通过区分抽象和具体计算任务,提升了理解与规划效率。而消融实验进一步证明了训练策略,尤其是多段迭代训练,对模型性能的决定性影响,为未来优化推理模型设计提供了理论和实践依据。
随着研究的深入,HRM的实现方式和理论基础或将被更广泛地应用到人工智能的其他领域,如机器人控制、自然语言理解及复杂决策系统,为智能体赋予更强的推理和自我修正能力。未来,结合更多元化任务和更复杂的层次结构,HRM及其衍生模型有望在人工智能的前沿领域继续发挥重要作用。 。









