在数据压缩领域,BZip2作为一种广泛应用的无损压缩算法,凭借其较高的压缩比和合理的性能表现,成为众多应用的首选方案。近年来,随着系统性能需求的提升及编程语言的多样化,如何用不同编程语言实现一个高效且竞争力强的BZip2编码器,成为开发者和研究者关注的热门课题。本文深入剖析如何在2024年利用Ada语言,从零开始在短短几天内成功构建一个高性能的BZip2编码器,并分享其中的技术要点与实践经验。 Ada语言以其可靠性、强类型检查及出色的并发支持而著称,广泛应用于航空、轨道交通及嵌入式系统等对安全性及稳定性要求极高的领域。选择Ada作为实现BZip2编码器的语言,一方面能够依托其严格的语法规则降低潜在的漏洞,一方面可借助语言内置的任务特性实现并行数据处理,提高编码效率。然而,面对传统上用C/C++等语言实现的BZip2编码器,Ada的生态环境和相关库相对有限,这也给新项目带来一定难度。
成功用Ada语言打造竞争力的BZip2编码器,首要的是掌握BZip2算法的关键组成部分。BZip2的压缩流程包含了块排序变换(BWT)、移动至前转换(MTF)、游程编码(RLE)、哈夫曼编码等阶段。每一步都严密依赖前一步的输出,且对性能影响巨大。尤其是BWT的全块排序需要高效的排序算法支持,如何用Ada实现满足性能需求的排序机制,是项目成败的关键之一。 在短时间内开发编码器的策略中,合理划分模块功能和进行精细化调试不可或缺。采用模块化设计,代码结构清晰,方便后期优化和维护。
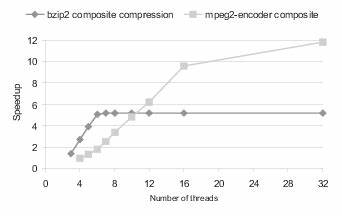
Ada语言的包(Package)机制天然支持这种设计风格,使得功能划分逻辑合理,接口简洁。开发过程中,先用简单的算法验证每个压缩阶段的正确性,再逐步替换为高性能实现,确保质量与速度双重提升。 另一个性能瓶颈是哈夫曼编码的构造与应用。由于Ada语言的灵活性,可以自定义高效的数据结构来存储哈夫曼树和编码表,提升编码速度。同时使用Ada的任务特性进行多线程处理,将不同数据块的压缩任务并行执行,有效利用多核处理器资源,显著提升整体吞吐量。 在编码过程中,内存管理的优化极为重要。
Ada支持显式的内存控制和堆栈管理,通过合理的内存布局和缓存机制,可以减少内存访问延迟,降低垃圾回收负担。针对BZip2压缩中频繁使用的缓冲区,设计高效的缓冲池,有助于提高内存利用率并减少碎片。 开发过程中借助Ada的强类型检查和编译时错误捕获功能,极大地提升了代码的健壮性和安全性。相较于传统的C语言实现,能有效避免许多内存泄漏、指针误用等隐患,这为编码器的稳定运行提供了坚实基础。 在调试和测试阶段,采用全面的测试用例覆盖各类输入数据,确保编码器的通用性和兼容性。同时通过基准测试不断比较与现有主流BZip2实现的性能差异,发现瓶颈并针对性优化,以达到或超越其性能水平。
进一步提升竞争力的措施包括引入硬件加速接口和算法层面的改良。例如,结合SIMD指令集对BWT排序进行加速,或者优化哈夫曼树构造算法以减少计算步骤。Ada支持调用底层汇编,便于整合这些硬件优化方案。 综合来看,用Ada语言在几天内从零开始开发一个性能优异的BZip2编码器虽然充满挑战,但经过合理规划与技术积累,完全可以实现令人满意的效果。这不仅展示了Ada语言在高性能系统编程中的潜力,也为类似项目提供了宝贵的开发范例。未来,随着Ada生态的进一步完善和更多优化技术的引入,这类高性能压缩工具的开发效率和成果必将迈上新台阶。
对于有意深入了解压缩算法实现或拓展Ada应用场景的开发者而言,掌握此类项目经验意义非凡。不仅能够加深对数据压缩理论的理解,还能提升系统设计及多并发编程能力。同时,这也推动了软件开发向更加安全可靠和高效智能方向发展,符合现代技术环境下的多重需求和挑战。