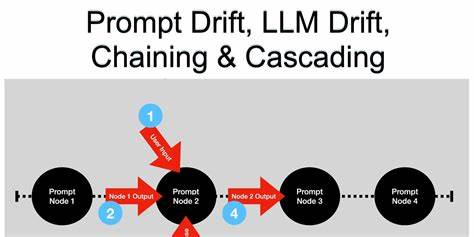
在人工智能技术飞速发展的今天,大型语言模型(LLM)已经成为赋能众多智能应用的重要基石。无论是智能客服、内容生成还是数据分析,LLM都发挥着不可替代的作用。然而,随着模型不断迭代升级,隐藏在背后的一个重大挑战——提示漂移(Prompt Drift)逐渐浮出水面,它可能在不经意间破坏现有信赖的系统稳定性。PromptDrifter应运而生,致力于成为开发者手中的坚实盾牌,帮助及时发现并应对提示漂移风险,保护生产环境的稳定与可靠。 提示漂移是指在大型语言模型版本更新或训练数据、模型架构发生微调后,即便输入的提示不变,输出的结果也可能产生变化。这些变化可能表现为格式差异、内容调整、甚至语义偏离等多种形式。
尽管这种现象体现了模型在不断学习和优化,但对于依赖稳定输出的应用场景来说,却是潜在的隐患。未能及时发现的提示漂移,容易导致下游系统出现故障、用户体验下降甚至业务中断,带来维护成本急剧上升和部署受阻等连锁反应。 PromptDrifter正是针对这一行业痛点,提供了一种便捷且高度自动化的解决方案。它作为一个开源项目,允许开发者通过简单配置,定义一组规范的提示测试用例,自动对LLM的响应进行比较和校验。每当模型生成的答案与预设的期望结果偏离超出允许范围时,PromptDrifter会立刻触发报警机制,阻止问题版本进入生产环境,确保整体系统的稳定持续运行。 PromptDrifter具备高度的灵活性和扩展性,不依赖于任何单一模型供应商。
无论是来自OpenAI的GPT系列、Anthropic的Claude、Google的Gemini,还是新兴厂商如Ollama、阿里巴巴的Qwen以及xAI的Grok等,均能通过其内置的适配器体系无缝接入。这种模型无关的设计理念,使PromptDrifter能够适配多样化的业务需求,扩展潜力巨大。 此外,PromptDrifter支持多种类型的漂移检测算法。除了基础的完全匹配、正则表达式匹配以及子串匹配外,更引入了基于语义相似度的检测技术,利用先进的句子向量模型进行深度文本比对。这种多维度的检测能力大幅提升了漂移捕捉的精准度和鲁棒性,减少误报和漏报风险。 对于持续集成和持续部署(CI/CD)流程,PromptDrifter同样提供了完美契合的自动化支持。
其官方提供的GitHub Action能够轻松嵌入开发管道,实现每一次代码提交或拉取请求时自动执行提示漂移检测。从而在版本变更早期阶段就发现潜在风险,防止带有漂移的模型响应流入生产环节,极大提升了开发效率和产品质量保障。 在实际应用案例中,使用PromptDrifter帮助一个全球金融机构对接OpenAI GPT模型,通过定义关键业务场景的提示测试用例,成功捕获了GPT更新版本导致的格式变化与语义偏差,防止了潜在的客户服务故障和法律合规风险。类似案例证明PromptDrifter不仅是技术工具,更是企业建立可靠智能服务的关键保障。 对于开发者而言,PromptDrifter的入门门槛较低。只需通过pip命令安装并初始化配置文件,编辑YAML格式的测试用例,便可启动对多个提示的自动化检测。
丰富的文档和活跃的社区支持,也使学习和使用过程变得更加顺畅。此外,开源性质意味着开发者可以根据自身需求进行定制和扩展,推动项目不断完善和多元化发展。 未来,随着大型语言模型生态的不断壮大,提示漂移的管理和监控将更加重要。PromptDrifter作为前沿工具,计划支持更多主流模型和云服务,提升检测算法的智能化水平,并扩展更多自动化集成功能,帮助各行各业全方位守护语言模型应用的安全与稳定。 总体来看,PromptDrifter不仅提供了一套科学有效的提示漂移检测解决方案,还以其灵活、开放和自动化的特性,帮助开发者在高速发展的AI领域保持敏捷与自信。通过降低因漂移带来的意外风险,它助力企业在确保质量的同时,释放LLM潜力,推动智能化应用迈上新台阶。
对于任何依赖大型语言模型的团队而言,PromptDrifter无疑是提升产品竞争力和用户价值的理想利器。