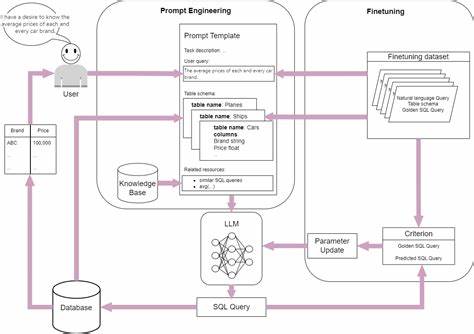
随着人工智能技术的迅猛发展,大型语言模型(Large Language Models,LLMs)在自然语言处理领域展现出前所未有的潜力,特别是在复杂的文本到SQL(Text-to-SQL)任务中备受关注。文本到SQL任务旨在将用户的自然语言查询准确转换为对应的SQL语句,使数据库操作更加智能化和便捷化。但这一领域的挑战依旧显著,用户查询的多样性、数据库结构的复杂性,以及SQL语法自身的复杂度,均对模型提出了极高的要求。面对这些瓶颈,LiveSQLBench作为最新推出的评测基准,为大型语言模型在真实世界的文本到SQL任务提供了一个动态、持续更新且无污染的测试环境。LiveSQLBench由香港大学BIRD团队与谷歌云合作开发,定位于通过高质量、多样化且真实复杂的数据集,推动LLMs在文本到SQL领域的实际落地与性能提升。LiveSQLBench的设计理念秉承公平、开放与创新,项目首发版本LiveSQLBench-Base-Lite包含了18个面向终端用户的数据库,涵盖270个任务,这些任务通过严格的专家团队策划,确保用户查询表达无歧义且SQL语句复杂度处于中高级水平。
每一个任务都配备了金标准的SQL答案,并通过自动化测试用例进行有效验证,保障评测结果的准确与可重复性。LiveSQLBench的数据库实时动态构建,依托丰富且定期更新的CSV数据源,覆盖从小型终端用户规模(约127列)到工业级巨型数据库(超过1340列)多种规模,充分考验LLMs的跨规模适应能力和扩展性。更为特别的是,LiveSQLBench引入了层级知识库(Hierarchical Knowledge Base,HKB)支持,知识点之间设有关联链条,促使评测任务涵盖多跳推理能力。HKB提供结构化的JSON格式及非结构化的文档格式,体现了模型跨模态、多层次理解的综合能力。在SQL覆盖面方面,LiveSQLBench不仅关注传统的SELECT查询(偏重商务智能BI场景),更结合了CRUD操作(包括UPDATE、CREATE等数据库管理指令),全面反映现实数据库操作的多样需求。这一点使得LiveSQLBench成为目前支持最广泛SQL语法谱的新型评测基准。
评测环境方面,LiveSQLBench提供基于Docker的标准化评测平台,便于模型部署运行和结果重现。每一次发布均包含公开开发集和隐藏测试集,隐藏测试集将转化为后续版本的公开开发集,保证了评测的持续进化与公平性。首次发布的LiveSQLBench-Base-Lite已于2025年5月底上线,迅速吸引了业界和学术界的广泛关注。榜单显示,OpenAI的o3-mini模型以47.78%的成功率领先,紧随其后的是GPT-4.1和Anthropic的Claude Sonnet 4。各模型在准确生成SQL语句方面存在明显差距,证明文本到SQL仍是LLMs面临的巨大挑战。LiveSQLBench不仅为模型当前能力提供了公正的评判标准,还为后续的技术突破提供了清晰的目标和方向。
尤其值得关注的是,项目正在积极开发更大规模的版本,包括LiveSQLBench-Base-Full,计划添加600个业务智能任务和200个管理任务,以及LiveSQLBench-Large-Lite和LiveSQLBench-Large-Full,后两者将引入工业级庞大数据库和文档形式的知识库,进一步扩充任务覆盖范围和复杂度。此外,LiveSQLBench计划支持多种SQL方言,已初步启动SQLite的研究支持,未来或将通过社区投票拓展更多数据库类型,提升评测的全面性和通用性。LiveSQLBench的独特价值还体现在其注重动态交互的能力——通过与BIRD-Interact结合,实现对LLMs在动态对话和代理任务中的文本到SQL转换能力的考察。此举不仅模拟真实用户与数据库之间的交互场景,也推动了智能数据库助手等实际应用的落地。作为一项前沿基准,LiveSQLBench必将推动人工智能数据库界面接口技术迈向新的高度,为数据科学家、开发者和企业提供强有力的工具支持。未来,随着更多任务类别、多语种、多方言数据库的加入,LiveSQLBench有望成为全球文本到SQL领域最具权威性和活跃度的评测平台。
研究者可利用其公开且持续更新的数据集合,深度挖掘语言模型的推理潜能和泛化能力。开发者则能基于评测结果优化模型架构、训练策略及工具集成,提升产品的稳定性及用户体验。综上,LiveSQLBench是一款划时代的文本到SQL评测基准,以其动态演进、无污染设计、多样真实场景覆盖等特点,为大型语言模型的数据库接口能力提供了清晰的性能标尺和前瞻性的技术方向。无论是学术科研还是产业应用,LiveSQLBench都展现出不可替代的重要价值,值得深入关注和广泛应用。