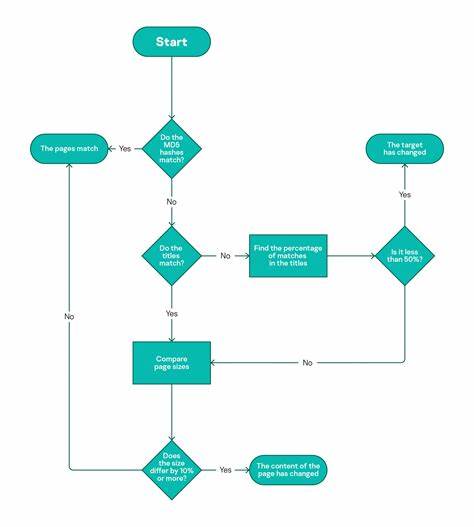
近年来,人工智能技术迅速发展,正逐渐渗透到社会治理的各个层面,尤其是在公共福利领域。阿姆斯特丹,这座历史悠久的欧洲城市,尝试通过一项名为“智能审核”(Smart Check)的算法系统,对每一位福利申请人进行风险评估,以便提高效率、减少欺诈行为,并实现社会资源的公平分配。然而,这场看似前沿的高风险实验,却因算法偏见和伦理争议引发社会各界广泛关注与反思,最终以项目的取消告终。 阿姆斯特丹的初衷是通过智能系统替代人为主观判断,以降低人类偏见和故意疏漏带来的误判风险。该系统基于机器学习模型培训,结合历史福利调查数据,试图识别可能提交虚假信息的申请人。项目开发团队在设计阶段有意识地剔除直接与性别、民族等敏感特征相关的变量,旨在避免传统的歧视问题,同时采用解释性增强算法(Explainable Boosting Machine),以便政策制定者和受众更好地理解模型决策逻辑。
尽管项目组严格遵循当下“负责任人工智能”的理论框架,聘请数据科学家进行连续调整,实施多层次的偏差检测和校正措施,乃至广泛征求公众和专家意见,实验期间仍暴露出诸多不可忽视的问题。首轮测试显示算法对非本地居民和男性申请者存在过度怀疑,误判率显著高于其他群体。虽然随后通过调整样本权重一定程度缓解了这种情况,但实际运行时偏差反复出现,且新形式的偏见相继浮现,例如对有子女的申请人产生不公平待遇。 这场实验也暴露出使用历史数据训练模型本身存在的根本矛盾。以过往调查结果为输入,意味着任何历史数据中潜藏的偏见或错误都极易被复制和放大。更为复杂的是,所谓的“公平”定义本身在学术界和公众间存在多重解释,无法通过单一数学模型完全涵盖现实社会中的复杂交叉身份和利益关系。
阿姆斯特丹的做法是力求“平等分摊错误调查的负担”,然而此定义下的公平性依然难以满足不同群体的全部合理诉求。 在伦理监督方面,市政府成立了参与委员会,由福利受益者和权益倡导者组成,作为项目的独立监督力量。该委员会自始至终对智能审核持批评态度,质疑项目是否切实尊重受助者的基本权利和尊严。委员会成员强调,持续监控和怀疑是福利申请者日常生活的一部分,自动化算法可能使这一压力倍增且难以申诉。与此同时,市议会内部部分成员因未被充分告知项目进展而表达不满,认为项目缺乏透明度与民主审议过程。 最终,经过数月的实际应用和数据分析,项目团队不得不承认智能审核未能达到预期目标:其无法有效减少被错误标记的福利申请人数量,也没有超越人类工作人员的准确率。
更重要的是,算法偏见问题难以根治,可能导致社会信任度下降,对弱势群体的潜在伤害日益显著。在2023年底,阿姆斯特丹正式宣布终止智能审核计划,决定回归传统人工审核系统。 事件引发的反思在社会各界持续发酵。首先,即便有再多的技术手段和伦理工具,人工智能在极易触及个体基本权利和社会公平的领域中,尚未做到真正公正且无害。设计者与决策者必须正视技术局限及其背后的社会结构性问题,仅依赖算法难以解决深层的信任与不公。其次,公共政策制定过程中,充分的参与性和透明度尤为重要。
受影响群体的诉求不能仅停留在表面征询,而需融入实际权力分享和监督机制,避免“技术洗白”和单方决策。 此外,智能审核失败的教训亦显示,构建“负责任人工智能”需要面对诸多现实挑战,包括数据偏差无法完全消除,公平标准多元且难以统一,偏见检测机制复杂且不完善,以及技术与人文价值之间的矛盾。许多学者和技术专家指出,算法应被视为社会实践的一部分,而非纯粹的数学对象,公民社会和受益者必须成为定义和调整公平标准的重要参与者。 阿姆斯特丹的案例具有全球意义,代表了多国政府在拥抱数字化管理同时,如何审慎应对人工智能带来的风险与不确定性的缩影。类似的福利AI项目在美国、法国、日本、印度等地均曾引发争议甚至政策调整。通过公开数据、透明机制和多方合作,社会各界逐渐形成一种共识:算法虽然有助于提升效率和透明度,但不能简化为技术万能论。
公平与正义需要建立在持续反思、包容对话和权力平衡之上。 面对未来,阿姆斯特丹及其他城市需要深入探讨“智能治理”的哲学和伦理根基,包括如何界定个人隐私与公共安全、自动化与人类判断的边界,以及技术进步与社会公正之间的耦合机制。或许更重要的是,处理社会问题的根本出路不在于单一依赖算法,而是通过增加人力资源投入、提升公共服务质量,加强社会支持网络来构建包容性更强的福利体系。 总而言之,阿姆斯特丹的智能审核实验体现了人工智能时代公共治理的复杂性与挑战。它提醒我们,技术创新必须服务于人类的整体利益,而不应成为剥夺基本权利的工具。公平不仅是技术问题,更是政治、社会和道德问题。
未来只有通过多方协作、开放透明和权利保障,才能在人工智能的浪潮中,实现更公正和人性化的社会管理。