在信息爆炸的时代,搜索引擎成为人们获取信息的关键工具。知名的开源搜索引擎Elasticsearch凭借其卓越的性能和丰富的功能,成为了许多企业和开发者的首选。2024年,一位开发者尝试设计一款名为SearchArray的搜索引擎,虽未达到Elasticsearch的标准,却为我们展示了搜索技术背后的复杂性和挑战。本文将深入探讨SearchArray的设计理念、性能表现以及与Elasticsearch的对比,帮助读者理解现代搜索系统的技术细节和优化策略。SearchArray的诞生源于将全文搜索功能整合进数据分析库Pandas的需求,试图用熟悉的数据科学工具链打造简易且实用的搜索解决方案。它通过实现基于BM25模型的词汇匹配和评分,支持基本的全文查询。
然而,与Elasticsearch的较量揭示了其在性能和效率上的显著差距,这不仅是简单的实现细节,更反映了专业搜索引擎背后深厚的工程智慧。2024年的测试基于BEIR套件中MSMarco Passage Retrieval数据集,涵盖约八百万文档规模。关键性能指标涉及NDCG@10评分、搜索吞吐量以及索引速度。结果显示,SearchArray的NDCG@10评分为0.225,略低于Elasticsearch的0.2275,准确性表现接近,但在搜索吞吐量和索引速度上却逊色不少,分别只有Elasticsearch的五分之一和三分之一左右。这种性能差异引发了“冒牌感”的共鸣,也成为深入理解搜索架构的有力起点。为探究差距原因,我们需要理解BM25模型中分数合成的核心机制。
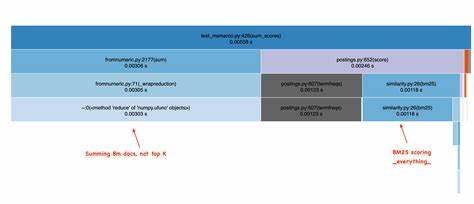
搜索词组如“luke skywalker”在BM25中实际上意味着文档分别对“luke”和“skywalker”两个词汇进行评分,并将这些得分通过某种数学方式合成总分。在SearchArray中,简单采用了对所有文档中每个词的得分直接求和的方法。表面上看,这种方式看似直观且简洁,但它忽略了更为智能的优化算法,例如Elasticsearch采用的WAND(Weak-AND)算法。WAND算法通过减少评分计算的文档数量,有效避免了对庞大词汇表的无谓遍历。更具体而言,罕见词如“skywalker”出现频率低,但对文档相关性的贡献显著,因此搜索引擎能优先深入处理这类词的倒排表,快速定位重要文档。而常见词“luke”则拥有庞大的倒排列表,若没有高效的跳转与剪枝机制,就会导致大量无关文档被无谓扫描。
SearchArray的做法是将每个文档所有词的BM25分数都计算出来,再进行数组相加,缺乏像WAND这类基于倒排表的剪枝,导致大量计算资源浪费。SearchArray独特的设计在于其内部索引结构并非传统的词项到文档ID的倒排表,而是基于位置索引,利用Roaring位图存储每个词项在文档中的位置。Roaring位图是一种高效压缩的数据结构,支持快速的位运算,有利于短语查询中的词序检测。通过对相邻词的位图进行位移和逻辑与操作,可以迅速确定短语出现的位置。这种设计在短语匹配场景极具优势,提升了定位文档中词序的效率。同时,凭借位图的popcount操作,SearchArray能从中推算出每个文档中词频。
这种不同于传统倒排表的结构带来灵活性和维护简易性的好处,但也限制了其在大规模文档排序和检索时的效率。除此之外,SearchArray的BM25实现中,很多不依赖于查询词的参数计算未加缓存,导致重复计算增加了延迟。诸如文档长度归一化等中间变量未提前计算存储,原本可以用数组预先缓存来减少查询时的计算成本。相反,成熟的搜索引擎通过缓存这类全局常量,进一步提升性能。从查询执行角度看,SearchArray利用用户自定义的Python代码调用NumPy数组进行词项评分求和,缺乏统一和智能的查询规划。这意味着用户必须自行组合评分逻辑,极易陷入效率瓶颈。
而Elasticsearch、Solr等建立在成熟查询DSL基础上的系统,可以对复杂查询进行计划优化、缓存和执行,带来更高效的搜索响应。SearchArray的设计理念强调原型开发与与数据分析工具链的融合,适合文档规模较小的数据集以及试验性探索。它的出现提醒我们,搜索引擎的高效实现融合了丰富的算法、索引结构和系统工程实践,远非简单的BM25计算叠加。对比Elasticsearch,我们应尊重专业搜索引擎开发者多年积累的优化方案和架构设计,认识到构建高性能搜索平台的艰难。未来,SearchArray以及类似项目若能引入更智能的评估剪枝算法,如WAND,结合高效缓存和查询规划,有望在保持灵活性的同时显著提升速度和吞吐量。此外,构建兼顾灵活表达和高效执行的查询DSL,将打开支持复杂、多来源检索需求的新大门。
也许下一代搜索系统会将数据分析与大规模检索紧密融合,在Pandas或Polars这类数据框架中直接实现高效Top-N检索与排序,让数据科学家能够无需切换环境便操作搜索结果。通过SearchArray的经历,我们更加理解到,在搜索领域,每一毫秒的性能提升,都离不开对算法细节、索引结构以及系统架构的深刻打磨。同时,开源社区中的创新尝试丰富了技术生态,为未来搜索技术的进步奠定基础。总之,SearchArray作为一款非专业级搜索引擎的探索成果,不仅揭示了搜索技术背后的复杂挑战,更激发了对高效、灵活搜索系统未来的期望。拥抱搜索工程师的智慧,也促使我们更加珍惜身边的成熟搜索引擎,为自主探索打下坚实基础。