在当今人工智能领域,大型语言模型(LLMs)因其强大的自然语言生成能力被广泛应用于文本生成、问答系统、对话机器人等多个场景。随着模型规模的迅速增长,如何提升模型推理效率成为业界关注的热点。KV缓存(Key-Value Cache)作为一种关键技术,极大地优化了推断过程中的计算资源利用率和响应速度。在深入学习和理解KV缓存机制之后,开发者能够更有效地实现和部署高效的语言模型,提升系统性能。首先,我们需要了解KV缓存的根本概念和背景。大型语言模型在生成文本时会逐字逐句地输出预测结果,每一步都会基于之前生成的上下文进行计算。
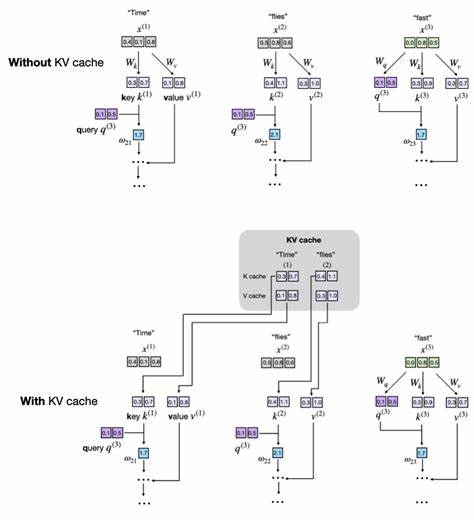
在没有缓存机制的情况下,每生成一个新词,模型都会重新计算整个已有序列的所有键和值向量,导致大量重复运算。KV缓存旨在解决这一瓶颈,通过保存之前计算过的键和值向量,避免重复计算,从而实现推理效率的飞跃。从结构上讲,KV缓存存储的是Transformer模型中注意力机制所需的键和值张量。这些张量用于计算注意力权重,决定模型在生成下一个词时应关注哪些上下文信息。借助缓存,模型在生成新标记时只需计算当前标记对应的键和值,随后将这部分数据追加到缓存中。后续步骤直接利用缓存数据,无需对先前标记重新求值。
实现KV缓存时,关键在于设计缓存的存储和更新策略。在一个通用的多头注意力模块中,我们通常会为缓存创建两个缓冲区,分别存储已生成标记对应的键张量和值张量。这样,每接收一个新输入,模型只计算当前步的键和值,并通过拼接操作将结果合并到缓存中。此操作确保缓存持续增长,覆盖完整的上下文信息。为了支持动态生成和适应不同的上下文长度,需要引入一个位置计数器跟踪当前缓存长度,确保新计算的查询张量能够正确对应缓存中的键和值。此外,还应提供机制在新文本生成开始时清空缓存,避免不同生成任务间的数据干扰。
与传统没有缓存的文本生成方式相比,KV缓存大幅减少了每步计算的复杂度,从原先的对所有以前生成标记重复计算降为仅处理当前新标记,实现了从平方级别到线性复杂度的跃升。特别是在生成长序列时,这一优化带来的性能提升尤为明显。然而,KV缓存的优势与挑战并存。显著提升的计算效率伴随着内存消耗的增加,缓存内容随着生成序列持续增长而不断扩大,对计算设备的存储能力提出更高要求。长序列生成时,缓存体积可能达到难以接受的规模,需采用合理的缓存管理策略,比如缓存截断或滑动窗口机制,限制存储长度,权衡速度与内存占用。另外,KV缓存实现上的细节同样影响性能表现。
简单的拼接操作虽然代码易读,但频繁的内存重新分配会引起碎片化问题,降低运行速度。对专业应用场景而言,预分配固定大小的缓存张量并在推理过程中直接写入对应片段,可以显著提升内存管理效率和计算速度。设计滑动窗口缓存时,需确保新数据遮盖旧缓存部分,同时维护缓存索引同步更新,保证网络计算的连续性与准确性。从代码角度来看,实现KV缓存关键在于对现有模型架构进行必要扩展,以支持缓存参数的注册、读写和重置。以多头自注意力模块为例,新增缓存键和值的PyTorch缓冲区,设置非持久属性避免训练期间保存。前向传播方法添加use_cache标志,控制是否使用缓存:首次调用时初始化缓存,后续调用中拼接新计算结果。
模型调用处需传递缓存参数,并合理更新序列位置计数。此外,新建清空缓存接口,便于在生成新序列前重置缓存状态,保证模型输出稳定。在实际应用中,将KV缓存融合进生成任务需要改写文本生成循环。利用缓存的版本会首先对整个上下文初始化缓存,然后在每次生成步骤中,仅传入最新生成的标记,避免对全量序列重复计算。这样不仅节约计算资源,也缩短每步生成时延。性能测试表明,即使是在不针对GPU或MPS等硬件进行特殊优化的纯CPU实现环境下,也能观察到数倍速度提升。
尽管训练阶段不可使用KV缓存,但推理期通过合理利用缓存,能够更有效地利用计算资源,为增强用户体验提供强大技术支持。此外,随着模型规模进一步扩大和支持的上下文长度不断增长,KV缓存的重要性愈加凸显。更大型的模型,如Qwen3和Llama 3,在未采用预分配缓存的情况下,缓存张量的存储将消耗数GB额外内存,这一压力促使研究人员探索如上所述的滑动窗口及内存预分配等多种优化策略。在部署实践中,权衡计算速度和内存占用,是选择缓存参数及管理策略的关键。值得注意的是,在GPU环境下,对于较小模型或较短文本,KV缓存未必带来显著加速,部分原因是缓存管理引发的设备数据传输开销抵消了计算提升。但在大规模模型和更长文本生成任务中,其优势则更加明显。
总的来说,KV缓存为大型语言模型的推理效率优化提供了切实可行的路径。通过缓存已计算的键和值,避免重复冗余操作,极大降低了计算复杂度。尽管实现细节和内存管理要求较高,但通过系统规划和合理设计,这种技术能够显著提升文本生成速度,助力模型大规模应用。对开发者而言,理解KV缓存工作原理,熟悉其代码实现,并掌握优化手段,是驾驭大型语言模型性能瓶颈的关键。未来,随着硬件发展和优化算法的迭代,KV缓存技术势必迎来更多创新和应用场景。持续关注和深入研究此类核心技术,将推动自然语言处理领域迈向更高效、更智能的发展阶段。
。









