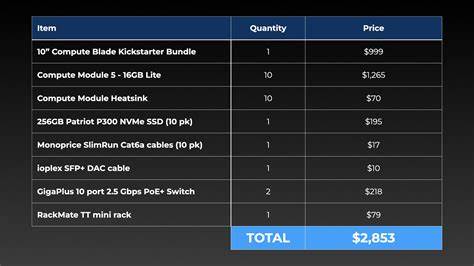
近年来,树莓派作为一种小型、低功耗且便携的计算平台,受到了无数科技爱好者和开发者的青睐。特别是计算模块的出现,更是推动了树莓派在集群计算、边缘计算和AI推理领域的探索。2023年,著名博主Jeff Geerling耗资约3000美元,打造了一台包含10个树莓派Compute Module 5(CM5)16GB版本的AI集群,期望借此实现高性能的分布式AI推理和计算处理。但事与愿违,这次经历给他带来了诸多反思,也为我们提供了宝贵的教训和洞见。树莓派AI集群的性能瓶颈、能耗效率、价格成本以及实际应用效果成为了本次项目的焦点。首先,Geerling在集群搭建过程中遇到了硬盘设备兼容问题。
初期使用的NVMe固态硬盘由于兼容性和稳定性不足,频繁出现故障,迫使他更换为性能更为稳定的Patriot P300系列固态硬盘。即使如此,Compute Module 5面临发热问题,导致处理器在高负载时出现降频现象,严重影响了计算性能。通过改进散热方案,固定安装专门设计的铝制散热片后,性能有所提升,但是相对于理想状态依然存在不足。性能测试环节中,他利用High Performance Linpack(HPL)测试了整个集群的浮点运算能力。未安装散热片时,集群峰值浮点运算达275 Gflops,相较于单个8GB版本CM5提升近8.5倍。改善散热后,性能进一步提升至325 Gflops,达到了10倍左右的性能扩展。
但相比同期售价约8000美元的4节点Framework桌面集群,树莓派集群的整体计算能力仍不足四分之一。能耗方面,树莓派集群表现出较好的效率。在集群满载时约消耗130瓦电力,折算每瓦浮点运算性能优于Framework集群,反映出在单位能耗上的一定优势。然而这种效率优势无法完全抵消性能上的明显落后,尤其是在价格对比中,树莓派集群的性价比显得并不突出。从AI应用角度看,集群的表现更为令人失望。尽管总计拥有160GBRAM资源,理论上能支持较大规模的AI模型运行,但由于树莓派5代CPU仅能通过CPU核心执行推理,GPU的Vulkan加速尚未被支持,导致模型推理速度缓慢。
例如,在运行Llama 3.2 3B模型时,单台树莓派通过CPU推理仅产出约6个令牌每秒,远逊于英特尔N100甚至Framework设备。对于更大的70B模型,必须拆分至多台设备并通过分布式推理完成,然而多节点通信和模型层分配的延迟导致推理速度急剧降低,Token生成仅有0.28个每秒,是Framework集群的1/25。其他分布式解决方案如Exo和distributed-llama虽能部分缓解问题,运行稳定性和性能提升有限,难以满足实际需求。总结Geerling的体验,树莓派AI集群在构建成本、性能、功耗、以及实用性等多个方面存在明显权衡。虽然设备小巧、低噪音且具备扩展性,适合对节点稠密度和分布式隔离有特定需求的场景,但绝大多数实际应用(尤其是高性能AI推理和通用计算)依然推荐选择性能更强、生态更成熟的商业服务器或桌面集群。树莓派AI集群的最大价值可能更偏向于学习、实验和特定边缘计算环境,比如需要多节点物理隔离的安全部署,或是持续集成任务等轻量级工作负载。
类似Unredacted Labs的Tor出口节点项目正是借助树莓派的低功耗和节点密度优势,打造高效的分布式节点网络。另外,市场上虽有诸如Gateworks GBlade这类专为工业应用设计的Pi计算刀片产品,具备更强网络能力和工业级可靠性,但因各种原因大多已停产,显示出此类产品难以在主流计算领域取得广泛认同。从更广阔的视角看,树莓派集群项目的挑战反映了当前小型单板电脑在AI高性能计算领域的局限。CPU性能相对不足、GPU加速支持不完善、网络延迟高和存储设备兼容性问题共同构成了性能天花板。未来若硬件生态及软件优化能持续推进,或许能够提升树莓派及类似设备的集群竞争力,但短期内很难与传统桌面及服务器平台抗衡。对于科技爱好者和DIY玩家,投入大量资金和时间打造树莓派AI集群,应具备清醒认知和合理预期。
它更适合用于学术实验、分布式系统原型开发及边缘计算探索,而非追求极致性能与商业级别的AI推理加速。总结而言,Jeff Geerling的树莓派AI集群案例为我们提供了宝贵的实践经验,提醒大家在构建集群和部署AI系统时要综合权衡成本、性能、功耗及维护复杂度。虽然树莓派集群具有一定的独特优势和趣味性,但面对高性能需求和多样化应用,现阶段它仍难以成为主流选择。未来随着硬件升级和生态完善,或许会迎来新的机遇,而当前阶段理性选择才是明智之举。 。