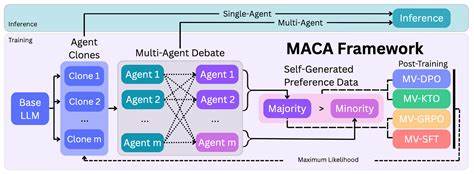
随着人工智能技术的不断进步,语言模型(LMs)在自然语言处理、机器翻译、智能问答等领域展现出强大的能力。然而,尽管现有的语言模型在生成文本方面表现优异,但其内部推理过程中的自洽性问题依然制约着模型的应用深度与准确性。语言模型常常在面对相同的提示时产生矛盾甚至相互冲突的回答,这不仅影响用户体验,更对模型的可靠性和实用性提出了严峻挑战。针对这一核心问题,最新提出的多智能体共识对齐(Multi-Agent Consensus Alignment, MACA)框架为解决模型的推理一致性困境带来了新的视角和方法。传统上,语言模型的推理一致性主要依赖于推理阶段的技术手段,例如多次采样后通过投票机制选出最优答案,但这种做法只是在表面上缓解不一致,未能从模型本身的思维轨迹和决策流程中根本解决难题。MACA通过将语言模型视为一群智能体,通过强化学习进行后期训练,实现模型内部多个智能体之间的深度对话与共识形成。
各智能体不仅独立尝试推理路径,更通过相互辩论,基于同伴的论证来不断更新和修正自身判断,避免简单的数量投票,而是生成更为丰富和深入的共识信号。这种方法让语言模型具备自我教育和自我修正的能力,促使模型在推理时更加果断与精炼,同时善于借鉴同伴思考,极大地提升了单智能体和多智能体环境下的推理表现。实验结果显示,采用MACA框架的语言模型在多个基准测试中表现优异,在GSM8K数据集上的自洽性提升高达27.6%,单智能体数学推理能力提升了23.7%,采样推理的成功率在MATH数据集上提升22.4%,多智能体集成决策在MathQA中的表现更是跃升42.7%。不仅如此,该方法对未见过的任务也表现出极佳的泛化能力,比如GPQA和CommonsenseQA上的性能分别提升了16.3%和11.6%。这些数据充分说明,MACA不仅显著增强了模型的逻辑一致性,还释放了语言模型潜藏的更深层次推理潜力。多智能体共识对齐的独特优势在于其鼓励模型内部形成稳定、一致的内在信念体系,使语言模型不再仅仅是对外部数据的反应器,而成为能够进行自我反思和自我调整的主动学习者。
这对于提升人工智能系统的可信度和稳定性尤为重要,特别是在复杂推理、长文本理解和多轮对话等场景中。通过强化学习过程中的激励调整,模型逐步学会辨别哪些推理路径更合理、哪些论据更具说服力,从而减少错误和矛盾的输出,提升答案质量和决策效率。展望未来,多智能体共识对齐不仅为语言模型的自洽性提供了有效解决方案,也为人工智能领域的集体智能、多智能体合作及其在动态复杂环境中的应用树立了前沿典范。随着技术的不断演进,这种方法有望成为推动AI向更高智能水平迈进的关键力量。整体而言,通过内化自洽性并借助多智能体的协同学习,语言模型正逐渐克服推理不稳定的瓶颈,迈向更加精准、可靠且富有逻辑的智能产出。未来的研究将继续聚焦如何优化智能体之间的沟通协议,提升共识形成的效率,以及扩展该框架在更多语言和任务上的适用性。
综合来看,多智能体共识对齐为解决语言模型推理中的一致性问题提供了全新的有效路径,为构建更具解释力和稳健性的人工智能系统开辟了广阔前景。 。