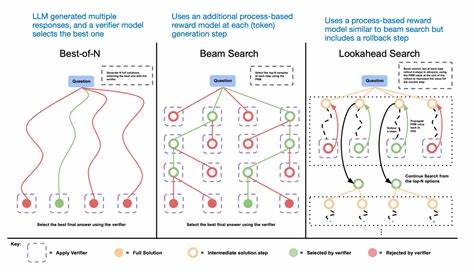
随着人工智能技术的飞速发展,大型语言模型(Large Language Models,简称LLM)在语言理解和生成领域展现出卓越的能力。然而,尽管它们在生成自然流畅文本方面取得了巨大进展,其推理能力,尤其是复杂数学和逻辑推理任务中的表现,仍存在局限性。近年来,研究者们尝试通过结合强化学习策略和树搜索算法,探索提升LLM推理能力的全新路径。奖励引导树搜索(Reward-Guided Tree Search)技术正是在这一背景下应运而生,成为推动LLM推理能力革新的重要手段。传统大型语言模型在推理时通常依靠前向生成机制,即根据上下文逐步生成答案。这种模式虽然高效,但在面对多分支、复杂的推理路径时容易陷入局部最优解,难以进行广泛的解空间探索。
此外,增加生成的“思考”步骤通常需要更多计算资源,如何有效分配资源成为一大挑战。奖励引导树搜索的核心思想是通过构建动态扩展的搜索树,结合策略模型和奖励模型,迭代优化推理路径选择。具体来说,策略模型负责在当前推理状态下确定下一步的行动或解题分支,而奖励模型则针对各条路径的推理结果给予评分,引导搜索算法优先选择高分路径,从而在复杂推理任务中实现更精准的解答。这种方法不仅充分利用了LLM本身的语言理解优势,还借助搜索算法的系统性探索能力,有效避免了盲目生成带来的低效和错误。“STILL-1”是该框架的一个典型实现,它综合了策略模型、奖励模型和搜索算法,动态构建解题思路树,评估和迭代优化解答路径。研究团队通过在多个数学推理数据集上的实验,验证了奖励引导树搜索显著提升了模型对复杂题目的解答准确率。
具体而言,STILL-1在处理需要多步逻辑推理的问题时,比标准的前向生成模型表现更稳定,对难度较高的问题具有突破性的解决效能。这一技术的最大优势在于其灵活的资源分配机制。测试时,模型可以根据问题的复杂程度,调整搜索的深度和广度,智能选择计算资源的投入,兼顾推理的质量和效率。此外,奖励模型的设计也至关重要。通过训练一个专门评估推理路径得分的奖励模型,整个搜索过程能够形成闭环反馈,使推理路线不断优化,避免陷入无效或错误的推理分支。这种方法的成功也启示了其他多步骤任务的智能求解,如程序合成、复杂规划以及跨领域知识推理等。
虽然奖励引导树搜索方案提出了新的思路,但其实施过程依然充满挑战。如何设计高效且准确的奖励模型,如何平衡搜索的探索与利用,以及如何在保持推理质量的同时控制计算资源的消耗,都是未来研究的重点方向。总的来说,利用奖励引导树搜索提升大型语言模型推理能力,标志着AI从纯生成迈向更智能、更系统的思考模式。随着技术的发展和优化,未来这类方法有望在自动化推理、教育辅导、科学研究等多个领域发挥重要作用,推动智能系统向真正理解与推理的方向迈进。对广大AI研究者和从业者而言,深入掌握奖励引导树搜索框架,不仅有助于突破现有模型的瓶颈,也将为智能系统带来更强的稳定性和泛化能力,开拓更广阔的应用前景。