在当今信息爆炸的时代,学术资源的快速增长对数据处理技术提出了更高的要求。尤其是学术论文,作为科研成果的重要载体,其数量和复杂度持续攀升。为了让人工智能更好地理解和应用这些知识,构建高效的学术论文索引并精确提取元数据显得尤为重要。通过对文献标题、作者信息、摘要等关键属性的结构化抽取,AI代理不仅能够实现语义理解,还能辅助推荐、检索和分析,极大提升科研效率和智能服务的质量。学术论文索引是指对论文文档进行系统化的处理,将论文内容分解为可识别和可检索的元素。它涉及到对PDF或其它格式文件的分割、文本提取、信息解析及语义编码等关键步骤。
现代技术借助自然语言处理和深度学习,能够实现对文本深层含义的感知,转化为向量嵌入,从而支持更智能的语义搜索和相似度匹配。元数据提取则侧重于抽取论文的结构化信息,如标题、作者姓名及其电子邮件、所属机构、摘要内容以及页数等。传统的手工标注方式既耗时又易出错,现代系统通过结合预训练大语言模型(LLM)和精细的规则设计,实现了自动高效的元数据识别与标准化。一个典型的索引流程首先从导入论文资料库开始,通常以PDF形式存储。利用高性能PDF解析库如pypdf,可以快速获取文档的基础信息,包括总页数及首要页码内容,这部分通常包含元数据丰富的摘要和标题内容。将首要页转换成易于处理的Markdown格式,是结构化文本分析的重要步骤。
转换工具如Marker能将复杂的PDF渲染转化为标准化的文本标记,简化后续的内容抽取过程。核心的元数据提取环节借助前沿的大语言模型。例如使用GPT-4o,通过特定的指令让模型从Markdown数据中识别并输出论文的标题、作者列表及摘要。这些信息通过数据类进行规范定义,便于程序自动解析和存储。为了支撑更智能的搜索,论文中的标题与摘要不会仅作为纯文本存储,而是进一步利用嵌入模型将其转化为向量表示。诸如all-MiniLM-L6-v2等SentenceTransformer模型能将文本语义映射到多维空间,从而实现基于语义的高效检索。
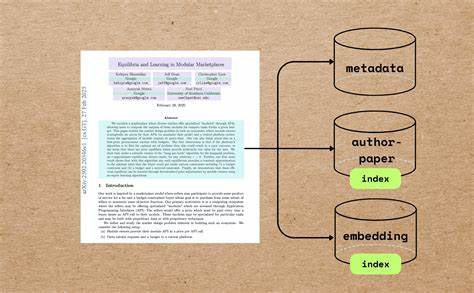
不仅如此,摘要内容往往较长,需通过语义标点及词汇规则进行合理拆分,分块后再分别嵌入,以确保检索的精准度和覆盖度。作者与论文的关联关系也是索引的重要组成部分,建立作者与其论文的映射表,支持按作者聚合查询,回答“某某学者发表了哪些论文”、“某位作者与谁合作过”等问题,赋能学术社交网络和合作分析。为保证跨时间的持续增量更新,推荐采用支持增量处理的关系型数据库,如PostgreSQL。其可扩展的架构配合PGVector插件支持向量检索,方便直接对嵌入数据执行余弦相似度等高效的相似性搜索,满足实时更新和高并发访问需求。在实际应用中,构建完整的学术论文索引流水线可以借助类似于CocoIndex的开源平台。它封装了从文件导入、PDF内容处理、大语言模型抽取,到嵌入生成及向量数据库导出的整个过程,极大降低了开发门槛。
用户只需定义简单的流水线和数据结构,即可实现复杂的语义索引功能。激活高效的学术索引方案,不仅有助于提升科研搜索引擎的响应质量,也促进智能论文推荐系统的精准度,推动知识图谱构建和科学文献的深入语义分析。未来,随着多模态数据(如图像、表格、代码)的索引能力提升,AI代理将能综合理解学术内容,打造更加丰富多维的智能科研助手。与此同时,隐私保护和数据合规性也应成为索引系统设计的重要考量,确保知识共享的安全和可信。总的来说,学术论文索引和元数据抽取代表了人工智能在科研信息管理领域的一个重要应用方向。通过技术和工具的不断迭代,研究者能够更快捷地获取精准知识,高效推进创新。
理解并掌握这一过程,不仅有助于构建面向未来的智能学术平台,更是实现科研数字化转型的关键所在。