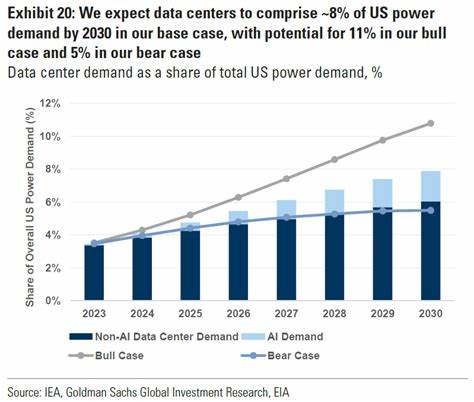
段落排版作为文本处理中的核心问题,在数字化时代的重要性不断提升。随着屏幕阅读和印刷排版技术的普及,高效且美观的排版算法成为众多开发者和研究者关注的焦点。传统的段落排版算法多采用局部贪心策略,虽然简单易实现,但无法保证整体排版效果的最优。本文将深入探讨一种基于折叠函数的段落排版算法,此方法源自计算机科学大师唐纳德·克努斯对段落填充算法的创新改进,能够在线性时间内实现优于经典贪心算法的排版效果。波澜不惊的文本排版,点滴之间尽显功力。首先,理解折叠函数在这里的作用是关键。
计算机科学中的折叠函数,尤指右折叠(fold-right),是一种递归地处理列表结构的函数。此处通过右折叠,算法从段落的结尾开始,逐步向前计算每个单词的“最佳断行方案”。这种自底向上的策略不同于传统先头向尾的贪心选择,使得整体断行质量大幅提升。算法的核心思想是将段落输入视为一个单词列表,每个单词通过折叠过程关联起断行信息。断行信息包括当前单词、从该单词开始构成的行包含的单词数量以及该断行选择对应的代价。代价是一种度量断行“坏处”的指标,数值越小表明断行越合理。
通过递归地计算每个单词对应的最佳断行并累积整个段落的断行方案,算法实现了对全局最优的近似。与此对比,传统的贪心算法往往只考虑当前上一行的断行,忽略之后文本的排版效果,导致整体段落排版不理想,甚至出现视觉节奏紊乱的问题。实现细节中,断行候选的枚举由辅助函数完成。该函数评估从当前单词开始依次加入单词至行中的长度累计,当达到或超过预设的最长行长限制时终止,确保行长度符合排版规则。断行候选中代价的计算基于行长度与目标行长的偏差平方,体现了对过短或过长行长度的惩罚,这种基于几何差异的惩罚函数在实际排版中表现良好。令人惊讶的是,断行候选函数的候选数量因排版限制而被严格控制,在最极端的情况下一行单词数目至多为最长允许长度的一半,这保证了算法整体的计算复杂度保持线性。
基于折叠的段落排版算法不仅理论基础扎实,而且极具实用价值。它保持了计算效率优势,适合处理长文本,同时避免了贪心算法可能导致的排版问题。尤其是在文本编辑器、电子阅读器以及排版系统中,该算法能够提供更优雅的阅读体验。更进一步,算法扩展潜力强大。当前版本的断行代价度量采用简单的偏差平方,但未来可结合语义信息、标点使用甚至行末断字权重,引入多维度优化策略,使段落排版更贴近人类审美和语言习惯。此外,算法的抽象体现了函数式编程思想的魅力,清晰定义类型如词(Word)、断行信息(Line-Info)以及利用递归与折叠函数实现复杂逻辑,为代码的可维护性和扩展性提供了坚实基础。
理解折叠函数在文本排版中的应用,也启示我们在其他字符串处理或数据序列优化领域中寻求类似突破,如代码格式化、日志清洗、语音转写断句等。尽管算法当前简化了一些现实中的复杂因素,例如统一假设每个词后跟单一空格,且忽略语法和标点上下文信息,但这些设定保障了核心算法的高效与准确。未来研究可围绕如何结合更多实际文本特性改进成本函数和断行策略展开。文章也特别指出,最后一行的代价被固定为零,反映了现实排版规则中允许段落结尾行短小的惯例。此细节体现了算法对排版语义的尊重,使得成品呈现更加符合阅读习惯。算法的底层逻辑既优雅又实用,不失为函数式编程在实战中的典范。
细细品味,我们看到一场条理清晰的力量:将递归、折叠以及代价最小化紧密结合,雕刻出令人满意的段落排版。因此,对于开发者及研究者来说,掌握此类算法具有深远意义,它不仅能够提升文本处理系统的智能化水平,还能借鉴思想推动其他相关领域的发展。总之,以折叠函数实现的段落排版算法无疑是现代文本处理中的亮点和利器。它突破了传统局限,以简洁的函数式结构和精妙的递归设计,实现了从局部到全局的排版优化,提高了阅读体验质量。随着技术的演进和应用需求的多样化,这类算法将持续展现其活力与价值,成为数字文字艺术的重要支撑和推动者。