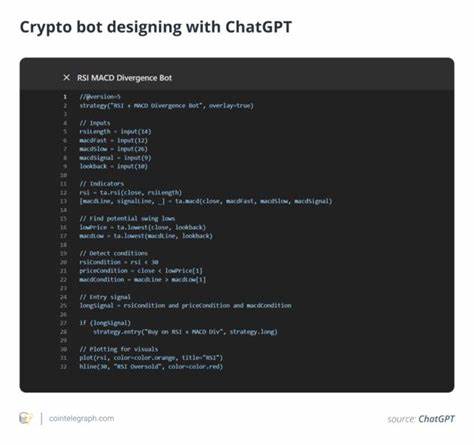
随着人工智能技术的不断进步,大型语言模型(Large Language Models,简称LLMs)在多个领域展现出强大的应用潜力,尤其是在自然语言处理和代码生成领域取得了显著成果。信息可视化作为理解和分析复杂数据的重要手段,近年来也逐渐成为研究与应用的热点。将LLMs引入数据可视化任务,为自动生成可视化代码和深入解读图表提供了新的可能性。本文将详细评估现有主流大型语言模型在可视化任务中的表现,探讨其优势与不足,并对未来发展提出展望。 数据可视化作为连接数据与用户理解的重要桥梁,通常依赖于专业的工具和编程语言如Python的Matplotlib、Seaborn或JavaScript的D3.js等。然而,对于非专业用户或者初学者而言,掌握这些技术存在一定门槛。
大型语言模型的出现,通过自然语言与代码的转换能力,为用户提供了便捷的生成可视化代码的途径。用户只需输入简单的文本描述,LLMs即可自动生成对应的数据可视化代码,实现快速展示。 目前广泛应用的一些大型语言模型,如OpenAI的GPT系列、Google的Bard和其他开源模型,都在代码生成方面展现出不同程度的能力。通过简单的自然语言提示,这些模型能够输出多种类型的图表代码,包括柱状图、折线图、饼图、散点图等,满足常见的数据展现需求。不仅如此,它们还能够处理不同的数据格式和参数设定,展现出较强的灵活性和适应性。 然而,尽管大部分LLMs能够生成可用的代码,但在精确控制可视化细节和复杂图表设计上仍存在一定的挑战。
模型在理解数据的语义关系和可视化目标时,偶尔会出现误解或生成代码逻辑错误。此外,复杂数据集和多维度可视化的生成,依赖模型对数据结构和领域知识的准确掌握,目前尚未达到理想水平。 除了代码生成,LLMs在理解和解释现有可视化图表方面也表现出专业潜力。例如,给定一张柱状图或饼图,模型能够通过分析图表描述回答相关问题,辅助用户深入理解数据背后的信息。这种能力在数据分析报告自动生成和智能问答系统中具有重要价值。 评估这些语言模型在可视化任务中的表现,需从多维度进行。
首先是代码生成的正确性和清晰度,生成的代码是否能直接运行并呈现预期图表;其次是对复杂需求的响应能力,如自定义颜色、坐标轴调整和图例显示等细节处理能力;再次是模型理解视觉表达的准确性,能否正确理解和解释图表内容。上述指标共同决定了模型实用性的高低。 研究显示,虽然现阶段LLMs已有较好表现,仍因训练数据限制、理解能力和任务复杂度等因素,存在不稳定和欠佳的表现。部分模型会生成多余或冗长代码,导致可视化效率下降,也可能未能充分反映用户预期。未来,结合领域特定数据训练、强化学习和多模态融合技术,有望提升模型对可视化需求的响应精度和智能水平。 与此同时,信息可视化系统本身也可借助LLMs实现交互体验的升级。
通过自然语言接口,用户无需掌握专业知识即可创建、调整和解释图表,极大降低了使用门槛,促进科学决策和数据驱动文化的普及。未来,我们可能见证LLMs与可视化工具深度集成,构建智能化、个性化的数据分析平台。 值得注意的是,LLMs生成代码和解释图表时的透明度和可信度也是重点关注问题。模型的生成依据往往缺乏解释,这在科学研究和敏感数据分析场景中可能带来风险。为此,开发可解释性强、具备验证机制的智能可视化辅助系统,成为今后重要方向。 总之,大型语言模型展现出在可视化任务中广阔的应用前景,既能辅助快速生成代码,也具备理解图表的潜力。
其应用不仅提升了数据可视化的效率与易用性,更推动了信息表达方式的变革。未来,通过持续优化模型架构和训练方法,融合更多跨领域知识,LLMs将在数据科学和信息可视化领域发挥更大作用,助力用户更好地洞察复杂数据,做出明智决策。