在信息技术快速发展的时代,数据规模正以惊人的速度增长。根据权威统计,到2025年全球数据总量将达到175泽字节,其中约80%的数据属于非结构化形式。面对如此庞大的非结构化数据,传统基于SQL的关键词搜索方法显得力不从心。关键词搜索依赖于文本中的精确匹配,不能有效捕捉同义词、隐含意图、多语言表达以及情感色彩,导致大量有价值信息被忽视。湖仓架构作为融合数据湖和数据仓库优势的现代数据平台,承载着日益复杂多样的数据类型和业务需求。如何在湖仓中实现高效、精准的非结构化数据搜索成为行业关注的焦点。
向量搜索和语义搜索由此应运而生,打开了非结构化数据智能查询的新方向。向量搜索基于将文本内容转化为数值向量,在高维空间中通过余弦相似度计算,快速找到语义相近的内容,而非单纯匹配字面字符串。这种搜索方式显著提升了对文本表达多样性的容忍度,使得“企业计划”不仅匹配关键词本身,同时还能关联“高级套餐”“保障正常运行”等语义相关的内容。语义搜索则进一步扩展了这一能力,专注于捕捉查询背后的深层含义,进而召回与用户意图贴近但词汇迥异的结果。例如,客户服务中搜索“退款不满”时,语义搜索能带来诸如“产品未达预期”“希望退货”等相关工单,极大增强了客服的响应能力和用户体验。然而,当前许多企业在湖仓生态中仍面临多系统割裂的挑战,传统分析数据库擅长结构化数据的快速处理,而专用的向量数据库则负责近似最近邻(ANN)搜索,两者往往分开部署,造成数据重复传输、延迟增加及复杂的治理难题。
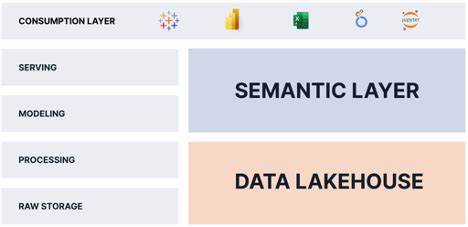
为解决这一瓶颈,e6data提出“统一而非迁移”的理念,将向量搜索能力无缝嵌入已有的查询优化器中。这样,同一张数据表可以同时支持传统的SQL查询和向量计算,无需额外的数据复制或独立集群,保持数据自治与安全一致。架构上的深度融合让处理过程更加高效,调度和缓存机制共享,令大规模数据检索不再是负担,而成为编译器优化层面的问题。具体来说,文本或多媒体数据首先经过如SBERT或OpenAI的text-embedding-3-large等高级语言模型转化为千维左右的向量表示。这些向量存储在数据湖中,利用诸如HNSW、SCaNN、DiskANN等索引结构支持快速的近似最近邻搜索。查询时,SQL引擎先进行传统过滤,缩减搜索空间,然后执行向量检索以获取语义相关项,最后整合返回结果。
这样的流程兼顾了精度和效率,也保留了SQL的强大表达能力。实际应用中,一条传统文本模糊匹配如“select * from reviews where review_headline ilike '%太贵%' limit 10”很可能错过大量表达类似感受的评论,而向量搜索的重写如“select * from reviews where cosine_distance(review_headline, '太贵') < 0.1 limit 10”则能召回更丰富、更语义贴近的结果,让数据价值最大化。此外,湖仓内置向量与语义检索还带来了治理与安全的优势,避免了数据流转到外部系统时产生的信息泄露风险。权限管理、审计和数据版本控制均可在统一平台完成,简化企业合规负担。随着自然语言处理模型和向量索引算法的不断进步,向量与语义搜索技术将在湖仓场景中扮演越来越重要的角色。它不仅让非结构化数据变得可搜索、可分析,还促使数据驱动决策更为智能化和人性化。
从客服自动化到市场趋势分析,从产品反馈研判到舆情监测,种种应用的背后都有这一技术的支撑。总结来看,湖仓中集成的向量与语义搜索打破了传统关键词检索的疆界,帮助企业穿透海量非结构化数据的迷雾,探索其潜藏的商业价值。它推动了数据平台由单纯存储与管理,向智能信息发现与洞察转型。未来,随着更多成熟的技术和实践落地,这一趋势将为数字化转型注入更强劲的动力,助力企业在数据洪流中抢占先机,赢得竞争优势。