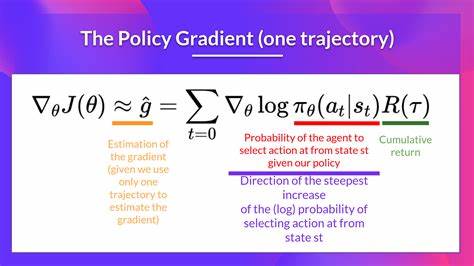
强化学习作为机器学习领域的一个重要分支,致力于让智能体通过与环境交互自主学习最优策略。在众多强化学习算法中,策略梯度方法以直接优化策略函数的方式,能够有效应对连续和复杂的动作空间,因而日益受到研究人员的青睐。随着深度学习框架的不断进步,JAX作为由谷歌开发的高性能数值计算库,凭借自动微分和加速计算的优势,成为强有力的工具,用于实现和实验先进的策略梯度算法。 策略梯度方法的核心思想是通过采样得到的轨迹来估计策略的梯度,从而沿梯度方向迭代优化策略参数。然而,传统的策略梯度算法往往面临梯度方差大、训练不稳定等挑战。为了克服这些问题,实验中引入了一系列增强技术,包括基线函数的使用以减少方差、熵正则化促进策略探索、梯度裁剪防止梯度爆炸以及每回合归一化处理提升训练公平性和收敛速度。
基线函数的引入是降低政策梯度估计方差的经典方法。具体来说,策略梯度的估计并非直接使用回报值,而是计算优势函数,即回报减去基线的偏差。通常选择基线为当前策略下回报的平均值,这样能够有效减少梯度估计的方差,从而加快收敛,提高训练的稳定性。实验代码中采用了JAX的数组操作方便高效地计算基线和优势函数,体现了JAX在表达数学计算上的灵活性和高效性。 熵正则化则是为了解决策略陷入局部最优、探索不足的问题。通过在损失函数中加入策略的熵项,算法鼓励策略保持多样性,避免过早收敛到确定性策略。
本文实验中设置了熵系数作为权重,平衡了策略的探索与利用。熵正则化的引入不仅提升了策略的泛化能力,也促进了更好的收敛效果,实验证明带有熵正则的策略在CartPole-v1环境中表现出更平稳的学习曲线和更高的最终性能。 梯度裁剪是一项简便且有效的技术,用以控制更新步长,防止训练过程中梯度爆炸问题导致参数震荡甚至崩溃。利用JAX配合Optax优化库,梯度裁剪被无缝集成到训练管道中,使得在反向传播阶段能够严格限制梯度范数。一旦梯度超过设定阈值,便自动缩放至合理范围内,这保障了训练的数值稳定性和策略更新的平滑性。 每回合归一化处理是另一项重要改进,针对不同回合长度和奖励分布带来的训练偏差,通过对回报进行均值和标准差标准化,确保每个回合的奖励贡献在相同的尺度上。
这样不仅提升了梯度估计的准确度,也避免了因极端奖励值造成的训练不均衡现象。在代码实现中,JAX的向量化和高效的统计计算显著加速了归一化处理的执行,体现了库在大规模强化学习数据处理上的优势。 本文实验主要以经典的OpenAI Gym环境中CartPole-v1为场景,系统地对比了基础VPG(Vanilla Policy Gradient)与集成上述增强技术的多种变体,量化了各项改进带来的性能提升。实验结果表明,加入基线函数能使训练收敛速度显著加快,熵正则化促进了更稳健的策略探索,而梯度裁剪则大大减少了训练波动,综合使用四项增强的完全版本在2000个训练回合后达到最高平均奖励,表明多种技术的结合对强化学习训练效果具有协同增益作用。 JAX在该实现中发挥了关键作用。它不仅支持高效的硬件加速(CPU、GPU以及TPU),还提供了强大的自动微分机制,极大地简化了复杂梯度计算的实现难度。
实验代码利用JAX的函数式编程特点,设计出整洁且模块化的训练流程,更容易扩展和调试。此外,配套使用的Optax优化库结合JAX的优势实现了灵活的优化策略定义,如梯度裁剪、学习率调整等,显著提升了开发效率和实验灵活性。 为适应不同需求,实验设计了各类命令行参数,允许用户灵活地开启或关闭基线、熵正则、梯度裁剪及回合归一化功能,同时支持调整学习率、熵系数等超参数。重复性良好的比较模式也方便研究者基于标准环境和参数设置,评估不同策略变体的性能,推动社区共享与协作。此外,代码还实现了训练过程的数据可视化,包含奖励曲线及损失函数变化,帮助使用者直观理解学习动态与模型优化趋势。 在强化学习领域,实验探究新的算法变体和训练技巧至关重要。
本文通过JAX实现的策略梯度实验,为广大学者与开发者提供了实践范例,展示了结合先进数值计算工具与策略优化技术带来的显著提升。未来可基于此框架,进一步探索自适应基线、层次化策略、策略混合或元学习等方向,实现更强大、更高效的智能体训练方案。 总结来看,利用JAX进行策略梯度实验不仅极大提升了模型实现的效率和稳定性,而且基于基线减方差、熵正则化、梯度裁剪及回合归一化等多重改进措施,实现了CartPole-v1上的卓越训练表现。该实验为强化学习研究注入了新动力,推动开发者探索更复杂现实场景下的智能决策问题。随着强化学习算法与硬件技术不断发展,期待JAX在未来政策优化和智能体训练领域发挥越来越重要的作用,助力打造更加智能和灵活的机器学习系统。









