随着人工智能的快速发展,大型语言模型(Large Language Models,简称LLMs)在自然语言处理领域中展现了惊人的能力,尤其是在对话生成、文本理解等多轮交互场景中。然而,传统大语言模型在流式处理长序列文本时,面临着极大的挑战,主要包括内存占用飙升和模型泛化能力受限两大问题。近期,一项名为“Efficient Streaming Language Models with Attention Sinks”的研究,为解决这些难题提供了创新视角和技术路径,推动了流式语言模型领域的进步。 在多轮对话或长篇文本生成中,模型需要不断地记忆之前的上下文信息,以保证语言生成的连贯性和准确性。目前主流的方法是在解码阶段缓存之前生成的所有Token对应的Key和Value状态(KV),从而实现对长序列的记忆和注意力计算。然而,当对话轮次增多,文本长度急剧增长时,缓存的KV数量爆炸式增加,导致系统内存负担加重,甚至无法运行。
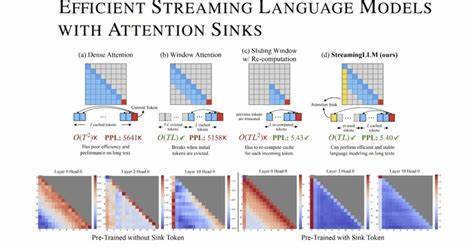
为降低内存消耗,滑动窗口注意力(window attention)机制应运而生,其只保留最近一段有限长度的KV,舍弃更早期的上下文。但实际应用中发现,滑动窗口方法在序列长度超过缓存容量时性能会急剧下降,影响生成效果。研究人员观察到一个有趣现象——注意力汇聚(attention sink)。具体来说,模型在计算注意力分数时,往往会强烈偏向某些初始tokens的KV,哪怕这些tokens的语义信息并不十分重要。换句话说,某些早期的上下文成为“注意力汇聚点”,吸引了大量注意力权重。这一机制被巧妙利用,保留这部分关键的初始KV,可以显著提升滑动窗口方法的文本生成质量。
基于这一发现,研究团队提出了名为StreamingLLM的高效流式推理框架。该框架无需对已有模型进行微调,便能够使有限长度注意力窗口的模型泛化到无限长序列处理。具体做法是在缓存管理上引入“注意力汇聚”的概念:保留所有初始token的KV不被丢弃,结合滑动窗口缓存近期新内容。此设计兼顾了长序列信息的传递和资源的节约,实现了流式生成任务中的内存与效率平衡。通过对Llama-2、MPT、Falcon、Pythia等多款主流预训练模型进行验证,StreamingLLM均展现出稳定且高效的长文本生成能力,支持处理多达400万token及以上的超长序列。相比传统全量缓存或滑动窗口重复计算基线,不仅速度提升高达22.2倍,还降低了系统资源的严格依赖,极大增强了实际部署的可行性和用户体验。
在StreamingLLM框架进一步的创新中,研究者还引入了占位符token作为专门的注意力汇聚载体,在预训练阶段植入该token,使模型在流式推理中更好地识别和利用注意力汇聚机制。这一设计使得流式部署的语言模型不仅性能更优,且推断过程更稳健,能够适应更复杂多变的交互场景。总结来看,效率与性能兼顾的注意力汇聚机制为流式语言模型突破了传统内存瓶颈与泛化限制,开辟了长序列自然语言处理的新天地。随着模型规模不断扩大、人机交互愈发丰富,对流式低延迟响应的需求持续增长,此类创新技术将成为推动大模型商业化落地的重要动力。此外,该研究还为未来探索注意力机制的优化策略、轻量级推理设计提供了理论与实践基础。展望未来,结合更高效的模型压缩手段和动态缓存策略,流式语言模型有望在对话机器人、智能助手、实时翻译等应用领域实现更广泛部署与应用,满足海量数据语境下的智能化需求。
整体而言,“注意力汇聚”作为流式模型中的关键现象,揭示了Transformer架构内部注意机制的新特性,赋能大语言模型在无限文本场景中展现更强的表达与理解能力。其背后的StreamingLLM框架不仅提升了系统运行效率,更为人工智能技术走向实用化铺平道路,彰显了前沿计算语言学领域的创新精神与技术潜力。随着学界和业界不断深化研究,相信高效流式语言模型必将引发新一轮技术浪潮,助力未来智能信息处理迈向更高台阶。