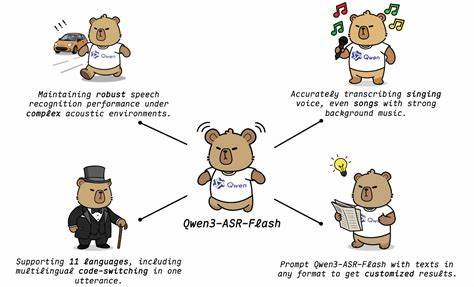
在人工智能和语音技术"风起云涌"的时代背景下,高效、智能的自动语音识别(ASR)技术成为连接人类与机器的重要桥梁。近年来,随着多模态数据和深度学习模型的快速发展,语音识别技术不断突破传统瓶颈,迈向更智能、更精准的新阶段。Qwen3-ASR-Flash,作为基于强大通用智能模型Qwen3-Omni打造的新一代语音识别服务,凭借数千万小时的庞大多模态ASR数据训练,实现了业界领先的识别准确率和卓越的多语言支持,成为语音识别领域的创新标杆。Qwen3-ASR-Flash不仅在普通语音转写中表现出色,还针对唱歌语音识别进行了特别优化,能够准确转录带有背景音乐的歌声,展现了其强大的环境适应能力和鲁棒性。 Qwen3-ASR-Flash支持包括中文、英文、法语、德语、俄语、意大利语、西班牙语、葡萄牙语、日语、韩语和阿拉伯语等11种语言,涵盖了多种方言和地区口音。在中文语种中,不仅支持普通话,还延伸至四川话、闽南语(福建话)、吴语和粤语等主要方言,体现了其对语言多样性的高度包容性。
英文部分覆盖英式、美国及其它多地区口音,满足不同用户群体的需求。多语言和多口音的支持,使得Qwen3-ASR-Flash能够应用于全球范围的语音识别场景,助力跨文化、高频交流的数字化转型。 技术上的一大亮点是Qwen3-ASR-Flash的上下文灵活引导能力。用户无需进行繁琐的上下文预处理,仅需提供任意格式的背景文本,模型即可根据提示生成定制化的识别结果。无论是关键词列表、长篇段落还是混合格式文本,甚至是部分无关或无意义的内容,都不会干扰整体识别效果。这种灵活的上下文偏置功能不仅优化了用户体验,也极大地提升了转录的适用场景和精度,满足特定领域或专业语境下的识别需求。
比如在直播解说、法律纪录、医疗速记等领域,Qwen3-ASR-Flash能够更精准地捕捉专业术语和重点信息,呈现最符合背景环境的转写效果。 性能方面,Qwen3-ASR-Flash在多个主流工业基准测试中表现优异,准确率超越众多竞品。其出色的非语音判别能力有效剔除静音、背景噪声等无关语音段落,保证了转录文本的纯净和精确度。此外,模型经过专门设计,能够适应复杂声学环境,无论是嘈杂的街头、车内噪音,还是多语种代码切换语境下,都能稳定输出高质量的识别结果。这种强大的环境适应性,扩展了其应用场景覆盖范围,使得办公、交通、媒体、教育等多个行业均能受益。 针对唱歌语音的识别是Qwen3-ASR-Flash的又一突破。
不同于传统ASR模型在音乐背景下往往识别困难的问题,Qwen3-ASR-Flash采用先进的声学建模和噪声抑制技术,能准确捕捉歌手语音信息,即使伴随复杂的背景乐器音轨,也能实现准确转写。这一点对音乐制作人、歌词版权管理以及娱乐内容自动生成等领域具有非常重要的应用价值。实现高保真度的歌唱文本转录,为音乐产业注入了全新的智能生产力。 Qwen3-ASR-Flash背后的数据规模和技术积累是其成功的基石。数千万小时的多模态数据覆盖丰富的语言、方言、口音和声学环境,支持模型从海量现实语音实例中学习多样化语音特征及口语表达。结合Qwen3-Omni大型通用模型的强大推理和泛化能力,使得语音识别服务不仅精准,还具备高度的泛化性和鲁棒性。
未来,随着持续的数据积累和技术迭代,Qwen3-ASR-Flash还将进一步提升识别表现,满足更多细分场景需求。 此外,Qwen3-ASR-Flash提供开放的API平台,方便企业和开发者集成该语音识别服务,实现自动转录、语音搜索、语音分析等多种智能应用。无论是移动端应用、云端服务还是本地部署,都能灵活适配,为不同业务场景提供定制化解决方案。诸如智能客服、语音助理、教育辅导、内容审核等多个领域都能借助Qwen3-ASR-Flash实现工作效率和用户体验的显著提升。 在全球数字化升级和智能交互需求日益增长的时代,Qwen3-ASR-Flash以其领先的技术实力、多样化的语言支持和强大的环境适应能力,成为推动语言智能革命的重要力量。用户能够享受到高质量、多语言、个性化定制的语音识别体验,加速信息获取和处理的智能化进程。
未来随着模型不断优化升级,Qwen3-ASR-Flash必将在智能语音技术浪潮中持续引领,助力社会各行业实现更便捷、高效的语言交流和知识传递。 综上所述,Qwen3-ASR-Flash代表了自动语音识别技术的新方向。其强大的多语言识别能力、灵活高效的上下文引导机制,以及卓越的唱歌语音识别性能,为用户带来了耳目一新的听觉体验和文本智能转写解决方案。面对日益多样化且复杂的语音环境,Qwen3-ASR-Flash无疑提供了一种更加智能化和人性化的答案,为未来智能语音交互奠定坚实基础。 。