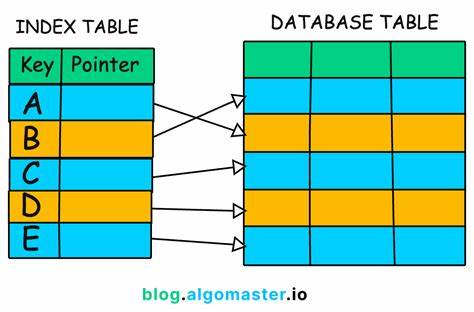
在大多数工程师的认知中,数据库的价值往往被事务、备份与写前日志(WAL)等机制所主导。然而,真正让关系型和分布式数据库成为可查询、可用且高效的数据平台的,往往不是日志本身,而是索引。索引将无序的数据堆转化为可导航的信息空间,是支撑低延迟查询和复杂检索的隐形引擎。 索引的本质是记录数据位置的映射,它将查询意图转换为对物理存储的最小访问量。没有索引,数据库只能进行全表扫描,性能在数据量增长时呈线性或更糟的退化。索引也并非单一形态,随着存储介质、查询模式和应用需求的演变,各类索引应运而生以解决不同问题。
B树是关系数据库中最常见的索引结构,适用于等值查找、范围查询和排序场景。B树通过分支和节点将键值有序存储,读写时能够在对数时间内定位到目标数据页。对于基于磁盘的传统系统,B树在随机读写之间提供了很好的权衡,因此成为大多数SQL数据库默认的访问方法。PostgreSQL、MySQL和SQL Server等都以B树为主干,通过页缓存、预读和填充因子等机制提升稳定性。 LSM树则是另一种重要范式,代表性实现包括RocksDB、LevelDB和Cassandra。LSM通过将写操作先聚合到内存表,然后顺序化地刷新为不可变文件,再通过后台合并(compaction)维护有序性,极大地提升了写入吞吐量和对SSD友好的顺序写性能。
LSM的代价在于读放大和后台合并的资源消耗,因此需要设计层级缓存、布隆过滤器和压缩策略来减少读取延迟和磁盘I/O。 地理信息系统对空间数据的查询需求催生了专门的索引结构,如R树、四叉树和GiST等。空间索引关注区域重叠、距离计算和邻近查询,而不是简单的一维键比较。PostGIS在PostgreSQL之上实现了丰富的空间索引与函数,使得地理检索能够用索引直接定位候选集合,而不必在海量坐标上进行暴力比对。 进入人工智能与向量检索时代后,向量索引成为新的关键技术。向量索引解决高维相似性搜索的问题,常见方法包含HNSW(分层小世界图)、IVF(倒排文件)以及基于近似邻居搜索的各种变种。
向量索引通过近似算法在海量向量中以子线性时间找到语义相似项,极大地降低了文本、图像和多模态搜索的成本。为了兼顾精度与性能,工程实践中常将向量索引与ANN库、量化技术和混合检索(先用向量筛选,再做精排)结合。 NoSQL数据库最初宣称能以更简单的方式替代传统关系库,但实际生产中发现,没有索引的存储几乎无法满足复杂查询需求。MongoDB早期就引入了B树与地理索引,后续又加入文本索引和向量索引;Cassandra在LSM之上也依赖二级索引与物化视图来支持非主键查询;DynamoDB虽然宣称"无索引",但依赖全局与局部二级索引来扩展查询能力。索引并不是关系范式的特权,而是所有数据平台实现可用性的核心要素。 索引带来的好处显而易见,但代价也必须被认真对待。
索引占用额外磁盘和内存空间,增加写入路径的复杂性,使得每次数据变更不仅要更新主表还要维护一个或多个索引结构。写入放大、维护事务原子性和索引一致性是工程实践中的常见挑战。索引缺失行会引起数据不可见,索引重复或指向错误则会导致数据重复或损坏,因此索引更新必须与表操作原子地绑定。 如何在工程实践中平衡索引的成本与收益?首先要基于查询模式进行设计,明确常见的过滤条件、排序字段与聚合需求。利用数据库的查询分析工具,例如EXPLAIN或执行计划,找到全表扫描、排序溢出和索引选择不当的热点。其次要以最小化写成本为前提,避免对高频写入列盲目建立过多二级索引。
对变动频繁但查询不频繁的列,可以采用部分索引或稀疏索引策略,仅索引与业务相关的子集以节省空间。 索引维护与监控同样关键。定期统计信息收集和分析可以帮助优化器选择更合适的访问路径。对于B树索引,控制填充因子、定期重建或重排索引可以减轻页分裂与碎片问题。对于LSM系统,合理配置内存表大小、压缩策略与合并优先级能够降低读写放大并稳定延迟。在向量索引场景中,索引重训练、量化参数调整与数据再分片是必须纳入运维流程的工作。
分区与分片策略可以放大索引的效果,使得索引维护在更小的物理范围内完成。分区能够减少单次查询扫描的范围,而分片则配合分布式索引或路由表将负载分散到多台机器。设计分区键和分片键时需要避免数据倾斜,选择能够反映查询热点的字段以提高并发效率。 索引的可扩展性与扩展方法对现代数据库至关重要。PostgreSQL之所以成为受欢迎的通用数据库,部分原因在于其可扩展的访问方法接口,使得开发者可以实现自定义索引类型和操作符。社区生态中出现了专注于新型索引能力的扩展项目,将全文检索、向量存储和专用分数模型无缝集成到关系引擎中,这使得数据库既保留了强一致性与事务保障,又能支持多样化的检索需求。
展望未来,索引的发展将更加贴合硬件特性和AI能力。随着NVMe和持久内存的普及,索引设计将更多考虑低延迟访问与并行化遍历。向量索引会演进出更多混合检索方案,结合语义理解与结构化过滤以提高检索精度与效率。自动化索引推荐与在线索引重排工具将逐步成熟,减轻DBA的日常维护负担。 对于开发者与架构师的实用建议是明确需求、衡量成本并持续监控。构建合适的指标体系以量化索引带来的查询加速和写入开销,采用渐进式索引策略先观察效果再推广到全量数据。
利用查询分析与慢查询日志定位瓶颈,通过覆盖索引、复合索引与部分索引等手段提升常见查询的命中率。在分布式环境下,关注一致性语义和索引更新的原子性,确保索引与数据之间不出现可见性差异。 总结来看,索引不仅是数据库的性能加速器,更是将数据转化为可查询知识的核心结构。从关系B树到LSM,从空间索引到向量索引,每一种索引都是应对不同查询维度的工程回答。理解索引的原理与权衡、合理设计与维护索引策略,才能让数据库在海量数据和复杂检索的现实世界中发挥出最大的价值。 。