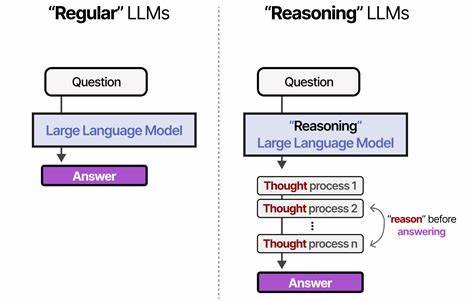
近年来,随着人工智能技术的迅速发展,大型语言模型(LLM)成为了自然语言处理领域的重要突破。然而,传统上,业界普遍推崇"深度思维"理念,即通过更复杂的模型结构、更深的网络层数和更庞大的参数规模来提升模型的理解和生成能力。虽然这种做法带来了显著的性能提升,但也产生了诸多弊端,例如计算资源占用过高、推理速度较慢以及模型生成信息有时过于冗长或不够精准。与此同时,越来越多的研究和实践开始关注另一种思维方式 - - "清晰思维",即强调模型能够以简洁、明确且条理清晰的方式理解和表达信息。本文将深入探讨为何清晰思维正在成为LLM发展的新趋势,以及其背后的技术原理和实际效果。清晰思维的核心在于通过优化模型结构和数据处理方式,使得LLM不仅仅停留在浅层的文本生成和模式匹配,而是真正实现信息的逻辑清晰和意图明确。
相比传统深度学习策略通过堆叠大量层数和复杂算子来追求更全面的"理解",清晰思维更注重将内容分解成条理清楚且无歧义的表达,避免嵌套的复杂论证和多余的语义累积,使得输出结果更为简洁有效。近期一款名为Class X的新型大型语言模型便是一例典范。它的开发团队放弃了单纯追求更深层网络结构的思维方式,而通过一系列架构层面的优化,如创新性的CLEU优化器设计,改进模型层间数据流动机制,以及定制的CUDA核函数来加速反向传播过程,极大提升了模型计算效率和训练稳定性。与此同时,最关键的成功因素来自于数据的精心筛选和标注。团队针对训练数据进行了严格把关,剔除了含有复杂嵌套推理的问题和高噪音信息,将重点放在简单却结构清晰、内容详尽且质量高的语料上。这样的数据策略帮助模型学会用简明、条理分明的语言表达思想,减少了以往深度算法容易陷入的模糊和赘述。
结合这种清晰思维导向的设计,Class X在多个自然语言处理任务中表现出色,尤其在逻辑推理、问答准确性和多轮对话的连贯性方面有显著提升。许多用户反馈指出,与部分市面上的"深度"模型相比,Class X给出的回答更直接,更易理解,从而在实际应用,例如教育辅导、内容创作辅助和客户服务场景中展现出更高的实用价值。此外,清晰思维的另一个优势是其优化了推理速度和资源消耗。传统深度结构往往需要大量算力支持,限制了模型的部署和响应效率。清晰思维通过提高数据和模型计算的针对性,减少不必要的复杂层数,使模型能够更快完成推断,降低能耗,有助于推动AI技术向更广阔的应用普及迈进。在推动清晰思维发展的过程中,数据的角色尤为重要。
精心筛选和注释优质数据,不仅为模型提供了清晰表达的典范,也为其在不同语境中的灵活应对奠定了基础。通过训练模型识别和避免复杂多层嵌套逻辑的陷阱,能够有效降低生成结果的歧义和错误率,从根本上提升了模型输出的可信度和用户体验。可以预见,未来大型语言模型的研究和应用将越来越重视"清晰思维"的理念。这一趋势不仅有助于解决当前深度模型面临的计算成本高、响应缓慢等技术瓶颈,同时也更契合人们日益增长的对智能交互精准、高效和易懂的需求。在语言理解和生成的道路上,放弃盲目追逐复杂和深度,转向关注如何让模型"明白自己在说什么",将成为推动AI技术更深层次变革的关键。总结来看,清晰思维凭借其注重逻辑简明和表达准确的优势,在LLM领域中展现出强大的生命力和广阔的发展空间。
架构优化和数据策略的双重保障,使得以Class X为代表的新一代模型不仅性能表现抢眼,也极大提升了用户体验和应用价值。在未来,围绕清晰思维的持续探索和创新,将为人工智能语言处理技术开辟崭新的发展路径,推动智能系统迈向更加智慧、可信和易用的新时代。 。