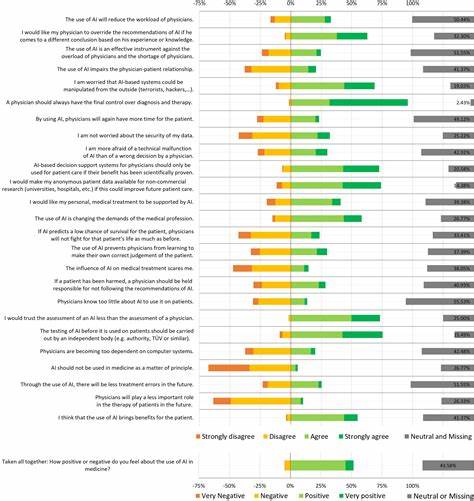
随着人工智能技术的飞速发展,大型语言模型(LLM)驱动的生成性代理在多个领域崭露头角,尤其是在模拟人类行为和意见调查方面表现出巨大的潜力。医疗领域作为高度依赖数据和准确决策的关键环节,正越来越多地借助这类技术来辅助获取患者意见、评估医疗决策和优化公共卫生策略。人工智能生成角色(AI Personas)以其无需暴露个人隐私、避免伦理风险的优势,成为医疗中进行意见调查和行为模拟的创新工具。然而,这一领域内的重要课题之一是,生成角色能否真实反映真实人群的多样化行为和态度,能否避免潜在的偏见并提供可信赖的研究数据。 最近一项由Yonchanok Khaokaew等学者发表在arXiv的研究,系统地对比了基于美国跨领域大型调查数据——Understanding America Study (UAS)中关于医疗决策的信息,与利用多种大型语言模型创建的数字孪生代理的回答表现,揭示了生成模型在医疗意见调查中的表现差异和潜在风险。研究发现,不同的语言模型在模拟现实决策行为时存在显著差异,部分模型倾向于产生不切实际的结果,例如低于实际的疫苗接受率预测,甚至出现所有虚拟代理均选择接种疫苗的现象。
这种过度一致性反映了模型可能内置的乐观偏见和对社会敏感背景的忽略。 在众多模型中,Llama 3表现出了更好的敏感性,能够较为准确地捕捉受访者在种族、收入层次等因素上的决策行为差异,较为细致地反映了社会群体间的多样化态度。然而,尽管如此,它仍然引入了与调查数据中不符的新偏见。这表明,尽管先进的语言模型在部分维度上能逼近现实,但其训练数据和设计哲学所带来的隐性偏见依然是不可忽视的问题。 AI生成角色在医疗领域调查数据中的应用并非单纯替代传统调查方式的技术革新,而是一种新的探索工具。与面对面访谈或传统问卷相比,数字孪生和虚拟代理能在无需暴露个人隐私的情况下大规模模拟多样人口群体,极大提升了行为研究的效率和安全性。
此外,这些方法具备快速迭代和实验的潜能,可以测试各种干预措施对不同群体的影响,帮助公共卫生决策者制定更有针对性的策略。 然而,AI模型模拟人类行为的负面影响和伦理忧虑也必须被充分重视。模型的训练数据多来自已有的互联网文本内容,难免包含社会上的既有偏见和刻板印象。这可能导致生成的虚拟角色在态度和行为上放大这些偏见,误导研究结论和政策制定。此外,模型的黑箱性质使得研究者难以完全解释其决策机制,增加了结果的不确定性。 为此,如何设计科学严谨的提示词工程,以确保生成角色能够真实反映多元化的社会背景和文化差异,成为关键。
研究团队在构建数字孪生时通过细致的人口统计学信息输入,力求减少生成结果与真实数据的差距。这种基于定制化提示的策略有助于提高模拟的多样性和精准度,但依然无法完全消除模型内隐偏见,需结合后续审查和校正机制,以保证数据质量。 另一方面,生成角色在医疗意见调查中的应用还需针对具体场景和需求进行不断调整。不同国家、地区和人群对医疗问题的认知和态度存在根本差异,简单地将一种模型或方法迁移应用可能造成误判和资源浪费。未来研究应该注重构建跨语言、多文化的生成模型和数据集,为全球医疗决策提供更全面、有代表性的数字孪生。 随着技术的发展,人工智能生成角色不仅能应用于意见调查,还具备模拟医生与患者互动、预测医疗服务需求、辅助心理健康评估等多重潜能。
这些应用的深入发展,有望革新医疗服务模式,提升患者体验和公共卫生响应效率。但与此同时,研究者和决策者必须严肃对待模型可能带来的偏见和伦理挑战,制定相应的规范和标准,确保技术造福于更多真实的人群。 总结而言,人工智能生成角色作为医疗意见调查的新兴工具,兼具深远的应用价值和亟待解决的挑战。其能力在于通过大型语言模型模拟多样化人群的医疗决策行为,推动行为科学研究和卫生政策制定迈向高效、智能化时代。未来需要加强多学科合作,结合社会科学、计算机科学和医学领域的智慧,完善生成模型的公平性和可信度,推动医疗领域更加精准和包容的意见调查体系建设。不断优化的数字孪生技术将成为连接虚拟与现实、机器与人类的桥梁,引导医疗创新和人类健康管理迈向更高水平。
。