随着数字化时代的快速发展,个性化推荐系统在众多互联网应用中扮演着不可或缺的角色。从电商平台到视频流媒体,推荐系统致力于精准捕捉用户兴趣,提升用户体验。然而,传统基于ID的推荐模型虽然效果卓越,却面临着诸多限制,如对新物品和冷启动问题的处理能力不足。生成式推荐系统作为一种新兴范式,将推荐任务转化为序列生成问题,逐步成为学术界和工业界关注的焦点。最新研究表明,生成式推荐在潜力无限的同时,也存在性能落后于成熟ID-based模型的现实挑战。为了突破这一瓶颈,协同分词(Collaborative Tokenization)和高效建模策略应运而生,成为提升生成式推荐能力的关键突破口。
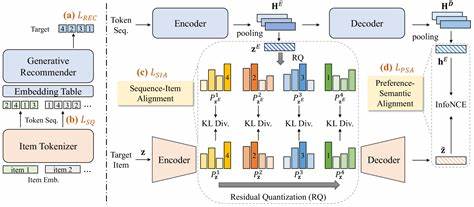
生成式推荐系统的基本思想是将推荐列表视作一段序列,通过学习预测序列中每个位置的物品token,从而实现个性化推荐。这一思路不同于传统推荐中简单地映射用户和物品ID,生成模型能够利用上下文信息捕捉更丰富的用户偏好动态。然而,现有生成方法常常采用基于内容的分词策略,忽视了用户行为中的协同信息,导致物品表达缺乏用户关联性,模型难以深度理解用户兴趣演变。 在此背景下,COSETTE方法的提出是一次重要创新。COSETTE通过对物品token的编码过程引入协同信息,实现了内容特征与用户交互数据的联合优化。其核心在于对物品表示进行对比学习,既考虑内容的重建准确性,也优化推荐相关性,确保物品token在生成序列时更具辨识力和区分度。
换言之,COSETTE赋予物品更具表达力的嵌入向量,使得生成器能够捕获潜在的用户-物品关系,提升推荐质量。 协同分词不仅提升了物品表示能力,同时也有效缓解了冷启动问题。传统ID-based模型面对新物品时往往力不从心,而COSETTE利用内容和协同信息的融合,使新物品即便缺乏丰富交互数据,也能通过内容特征与相似物品token的共享获得合理嵌入,从而实现更稳健的推荐。 除了分词策略的革新,模型架构本身的设计同样影响生成式推荐的效率与效果。主流生成模型多采用编码-解码结构,这种架构虽灵活,但计算资源消耗大,推理延迟高,难以满足大规模在线推荐的实时需求。为此,研究者设计了灵感源自音频处理的轻量级生成模型MARIUS,该模型通过分离时间线建模与物品解码两大模块,显著降低了计算复杂度。
MARIUS以高效的自回归机制捕获序列时间依赖关系,同时利用专门的解码器对候选物品token进行精准预测。这种解耦策略不仅减少了冗余计算,还增强了模型的泛化能力和稳定性。实验结果表明,MARIUS在标准的序列推荐基准数据集上,不仅降低了推理时间,还在准确率和覆盖率等关键指标上超越了传统编码-解码结构。 结合COSETTE与MARIUS的优势,最新的生成式推荐系统实现了性能上的飞跃。两者协同发挥作用,使得生成模型在保持灵活生成能力的前提下,有效封装了用户协同信息并提升了计算效率。此举不仅缩小了与现代ID-based模型如SASRec之间的性能差距,更在部分任务中实现了超越,标志着生成推荐的实用化迈出了坚实步伐。
生成式推荐的优势不限于性能提升,更在推荐系统的适应性和多样性方面展现潜力。由于生成模型能够模拟用户兴趣的动态演变与多样偏好,它们更适合复杂场景下的长尾物品推荐、多样化推荐和新兴内容推送。此外,生成框架对自然语言处理技术的高度兼容拓宽了推荐方式,例如结合语言模型实现多模态推荐、情境感知推荐等。 然而,生成式推荐也面临着挑战。首先,训练生成模型需要大规模且高质量的序列数据,数据稀疏性仍制约模型能力。其次,生成物品序列的解释性较弱,如何提升模型透明度和可控性是研究热点。
再者,在线部署中对低延迟和高吞吐的需求对模型效率提出严苛要求,这需要进一步优化架构和硬件实现。 未来方向看,融合协同分词与智能结构设计的生成式推荐有望进一步突破边界。多源协同信息融合,结合社交网络、地理位置、时间上下文等丰富信息将丰富token学习效果。同时,借助自监督学习和强化学习优化推荐策略,将推动生成模型在探索-利用权衡上的表现。此外,异构计算技术和模型压缩方法的融入,将极大助力生成推荐系统的工业级落地。 综上所述,生成式推荐系统正迎来革新浪潮。
通过协同分词技术如COSETTE提升物品表达,采用未来感轻量模型MARIUS优化计算流程,生成模型实现了精准与高效的完美结合。这不仅缩小了与传统强基线模型的性能差距,也铺设了通往更加智能和个性化推荐体验的道路。随着研究的深入和技术的成熟,生成式推荐必将在推荐系统领域发挥愈发重要的作用,推动互联网服务迈向更高智能水平。 。