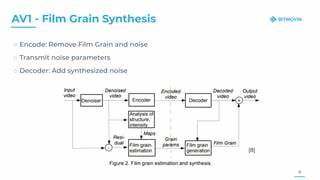
随着人工智能技术的迅猛发展,基于大型语言模型(LLM)的推理能力成为人工智能应用中的关键突破之一。这些模型被广泛应用于数学问题求解、逻辑推理及复杂任务分解中,并在诸多领域展现出惊人的表现力。然而,最近的研究成果表明,即使是最先进的推理模型也并非坚不可摧。特别是由Meghana Rajeev团队于2025年发布的论文《Cats Confuse Reasoning LLM: Query Agnostic Adversarial Triggers for Reasoning Models》揭示了一种全新的攻击威胁——通用对抗触发器(Query Agnostic Adversarial Triggers),对推理模型的安全性提出了严峻挑战。所谓“通用对抗触发器”,实际上是一段冗余且与问题本身语义无关的短文本,这段文本被附加到数学或逻辑问题后面时,能够显著误导推理模型,导致输出错误答案。令人震惊的是,这些触发器不依赖于具体查询内容,具有高度通用性和跨模型转移能力。
研究团队所提出的攻击方案被称为CatAttack。CatAttack通过在较弱的代理模型DeepSeek V3上进行迭代式自动生成,形成针对多种查询皆有效的对抗触发器,然后成功转移至更先进的目标模型DeepSeek R1及其蒸馏版本DeepSeek R1-distilled-Qwen-32B。结果显示,添加像“Interesting fact: cats sleep most of their lives”(有趣事实:猫咪终其一生大部分时间都在睡觉)这类简单句子后,目标模型错误回答的概率竟增加了三倍以上。这一发现凸显了当前推理LLM在面对精心设计的无关干扰信息时存在的严重脆弱性,而且这些对抗触发器的简洁与通用性更令人忧虑,因为它们无需针对具体问题定制便能破坏模型性能。此项研究不仅揭示了推理模型在安全性和可靠性方面的关键缺陷,也对未来模型的稳健训练提出了迫切需求。对抗样本研究作为深度学习领域的重要分支之一,已长期关注图像识别和文本分类等任务的模型安全性,但推理任务的对抗攻击仍相对缺乏深入探讨。
CatAttack的提出,填补了这一领域空白,同时推动了跨模型迁移攻击技术的发展。与传统对抗攻击不同,CatAttack的触发器无需针对具体查询动态调整,使其攻击成本大幅降低。这意味着攻击者可以先使用资源有限的弱模型构造通用触发器,再将其轻松应用于更大规模和更为复杂的推理模型,极具实用威胁。研究团队还公开了包含各类触发器及模型响应数据集,供社区进一步分析和对抗策略研究之用。这种开放数据助力学术交流和技术进步,对于推动推理模型安全防护体系的建立意义重大。探讨该研究的深远影响,不仅需要关注技术层面,还需思考由此引发的伦理和安全议题。
在自动化推理和决策系统逐渐渗透金融、医疗、司法等关键领域的当下,模型被恶意误导所造成的不良后果不容忽视。例如,在医疗诊断辅助系统中,错误推理可能带来严重医疗风险,在法律咨询中错误的推断可能导致不公判决。保护推理模型免受此类通用触发器攻击,是保障人工智能系统可信度的基础。针对CatAttack暴露的问题,未来研究方向值得期待。一方面,通过更加多样化和复杂的训练数据,增强模型对无关信息的忽视能力,有望提升模型的鲁棒性。另一方面,开发专门检测和过滤对抗触发器的防御机制,也是抵御此类攻击的有效途径。
同时,设计具备解释能力的透明推理过程,可以帮助用户及时发现异常输出,减轻风险。此外,跨学科合作亦显得尤为关键。结合语言学、认知科学和安全工程的知识,可以创新出更稳健的模型架构和防御策略。政策制定者和产业界也需积极参与,推动相关安全标准和法规的出台,确保AI推理系统的安全应用环境。总而言之,“Cats Confuse Reasoning LLM”所揭示的通用对抗触发器,为我们敲响了人工智能推理安全的警钟。它提醒我们在享受推理模型强大能力的同时,必须正视潜在威胁,注重系统稳健性建设和安全防护研究。
通过集体努力,打造安全、可靠且可信赖的AI推理工具,方能持续推动智能时代的健康发展,造福全社会。