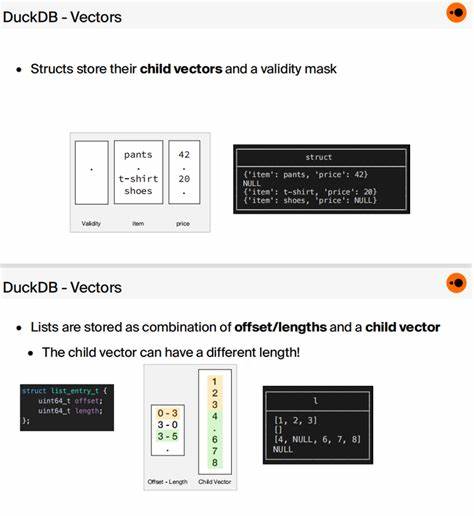
为什么要在关系型分析环境里采用稀疏数组存储 随着推荐系统、文本检索、特征工程与向量检索应用的普及,越来越多的业务需要处理高维向量。向量维度可以轻易达到数百、数千甚至数万,但在很多实际问题中,向量本身是高度稀疏的,非零元素只占极小比例。将整段向量以密集数组形式保存会造成巨大的存储和 IO 负担,同时在查询处理时频繁读取零值也浪费资源。DuckDB 作为嵌入式分析数据库,支持将稀疏向量以索引-值对的格式存储,从而显著减少磁盘占用和网络传输成本,并在常见计算上获得性能提升。稀疏数组的存储形式与 DuckDB 的约定 在 DuckDB 稀疏数组函数集约定中,稀疏数组使用索引数组 inds 和对应的值数组 vals 来表示。同时需要明确向量的总长度 K(即原始密集向量长度)。
索引采用 1 开始的下标约定,这与 DuckDB 的数组约定一致。例如原始向量 [7, 0, 0, 0, 23] 可以表示为 K=5,inds=[1,5],vals=[7,23]。这种索引-值对格式不仅节约空间,而且便于对索引列进行条件过滤,例如快速查找包含某个特征的记录。DuckDB 提供的一组稀疏数组函数 DuckDB 社区实现了一组常用的稀疏数组函数,能在 SQL 层面直接操作稀疏表示,使得复杂向量运算无需在客户端展开或额外转码。主要函数包括 sparse_list_extract、sparse_list_select、dense_x_sparse_dot_product、sparse_to_dense 和 agg_array_sum。这些函数的语义相对直观,支持在查询中直接调用,从而在数据库内部完成大量向量计算和聚合。
sparse_list_extract(position, inds, vals) 该函数返回给定位置的元素值,位置使用 1 开始的索引。如果索引在 inds 中存在,则返回对应 vals 的值;否则返回零。典型使用场景包括对单个特征值的筛选与过滤。举例说明,若行记录的 inds 为 [1,5],vals 为 [7,23],对 position=1 的查询将返回 7,对 position=3 的查询将返回 0。 sparse_list_select(positions, inds, vals) 该函数接受一个位置列表并返回这些位置在稀疏数组上的对应值,依旧遵循 1 开始索引约定。返回结果通常是一个大小与输入 positions 相同的数组,包含每个请求位置的值或零。
该函数在需要一次性抽取多个坐标值进行并行比较或上游特征合并时非常有用。 dense_x_sparse_dot_product(dense_arr, inds, vals) 该函数用于计算一个密集向量与稀疏向量之间的点积。由于稀疏向量只存储非零条目,点积计算仅需对非零索引处对应的密集向量元素进行乘加,极大减少计算量。例如对密集数组 dense_arr=[0.1, 0.2, 0.3, 0.4, 0.5] 与稀疏表示 inds=[1,5], vals=[7,23],点积为 0.1*7 + 0.5*23。在向量相似度过滤、召回阶段筛选与倒排快速打分中,密集向量乘以稀疏权重的场景非常常见,利用该函数可将计算推向数据库引擎以减少数据传输开销。 sparse_to_dense(K, inds, vals) 该函数重建完整的密集数组,返回长度为 K 的数组,零值位置由未列出的索引填充。
该操作在需要将稀疏表示传递给只接受密集向量的函数时有用,但应谨慎使用在聚合规模较大或向量维度极高的场景,因为重建密集数组会消耗较多内存与 IO。 agg_array_sum(arrs) 该聚合函数对一组等长数组按位求和,返回单一数组结果。结合 sparse_to_dense 或直接对稀疏表示处理后进行合并,agg_array_sum 可以高效地对大量向量进行逐元素聚合,例如统计特征总和或计算批次内向量的累积权重。在使用时可将稀疏向量先转换为密集或在应用端对非零索引进行合并,相比对每行直接展开计算, agg_array_sum 可以让数据库内部完成向量级的合并计算。稀疏表示在存储和查询中的优势与注意点 对于高维却稀疏的特征空间,索引-值对的存储形式能够显著减少每行的存储字节数,尤其适合存储在列式文件格式如 Parquet 中并配合压缩算法。尽管通用压缩算法对重复零有一定的压缩效果,但显式稀疏编码通常能进一步降低存储占用并在查询时只读取必要列(例如只读取 inds 列来判断某特征是否存在)。
不过需要注意的是压缩带来的收益会因数据分布、压缩算法和块大小而变化,因此在迁移到稀疏存储前应对真实样本数据进行基准测试。另一个实践考量是索引列和数值列分开存放的策略。将 inds 与 vals 单独存为列能让查询仅扫描需要的一方,例如只基于索引存在性做筛选时无需读取数值列,从而节省 IO。DuckDB 的函数集遵循这一分离设计,因此在建表与导出数据至 Parquet 时也建议保持这种列级分离。性能与计算优化建议 在使用 dense_x_sparse_dot_product 这类函数时,应尽量把密集向量也放在数据库内并以列或数组列的形式存储,这样数据库可以在内部完成大部分计算,减少网络传输。对点积计算进行筛选下推可以显著提前过滤掉大量候选项,从而节省后续更昂贵计算的代价。
另一个优化是避免频繁地将稀疏向量转换为密集形式。sparse_to_dense 是有用的工具,但在高维场景下会带来内存峰值。如果应用可以直接消费稀疏索引和值,则尽量保留稀疏表示并利用数据库层面的稀疏函数进行运算。对于需要聚合大量向量的场景,优先考虑在数据库端使用 agg_array_sum 或先对索引做归并汇总再生成稀疏合并结果,避免逐行展开产生巨量临时对象。此外,查询计划中尽量将筛选条件放在靠前位置,用索引列进行快速剪枝,减少稀疏值读取次数。常见应用场景 推荐系统与协同过滤在推荐场景中,用户或物品的特征通常是高维而稀疏的。
将特征以稀疏索引-值对存储,可以在召回或召分时快速筛选包含某些关键特征的候选,并使用 dense_x_sparse_dot_product 将预计算的密集权重与稀疏特征求点积,完成高效打分。文本特征与词袋模型词袋或高维文本特征本身天然稀疏。用稀疏数组存储词频或权重能够大幅度减少磁盘占用量与内存压力。对短文本或查询的在线匹配,稀疏表示能让检索阶段以更小的开销筛出匹配候选。嵌入与向量检索在部分应用中,虽然常见向量(例如 Sentence Embedding)是密集的,但也有将稀疏编码作为压缩或可解释特征的方法。对于混合特征(部分密集、部分稀疏),可以把两者分区存储,利用 DuckDB 的函数在检索阶段进行联合计算,实现灵活处理。
日志与事件特征在时间序列或事件日志分析中,事件存在性经常更重要于频率值。将事件作为稀疏索引记录可以快速统计不同事件的覆盖情况或并行聚合有意义事件的分布。从密集向稀疏的迁移策略 在现有系统里迁移向稀疏表示时,首先选取代表性数据集做基准测试。通过采样计算稀疏编码后的平均非零条目数、索引值分布以及 Parquet 压缩前后的文件大小,得到潜在的存储与查询性能提升预估。编码过程可在数据预处理管道中完成,输出格式建议为 K 列(总长度)、inds 列与 vals 列三列分离存储。对每一列使用适当的数据类型,inds 使用合适的整型(通常较小的无符号整型可以节省空间),vals 则视数值范围选择浮点或整型。
在转换后,应更新上游查询逻辑以使用专门的稀疏函数完成既有的向量计算,避免在 SQL 中频繁展开为密集数组。基于索引的过滤可以直接利用 inds 列,而数值参与的计算则通过 vals 列输入专门函数。压缩、备份与兼容性考虑 虽然稀疏编码通常能显著降低存储,但在将数据导出到 Parquet 等列式文件时依然建议开启合理的压缩策略。部分场景下通用压缩已经能对重复零进行很好的压缩,因此总体增益会因数据分布而异。导出前请保证数据类型与上游系统兼容,并对 inds、vals 列加上注释或元数据,便于后续系统识别稀疏格式。在多系统集成场景中,若某些消费端不支持稀疏格式,则可提供批量或按需的密集还原接口,但要为这些操作设定资源限额与并发控制,防止重建密集数组时触发内存峰值。
实际基准与最佳实践经验之谈 在一次内部迁移实验中,团队将多维特征从密集数组转换为稀疏索引-值对,平均非零比例低于 5%。在对 Parquet 文件进行对比后发现,显式稀疏编码在某些分区能将文件大小缩小几十个百分点,但也有分区由于数据分散、索引较多导致压缩效果不及预期。由此得到的经验是:只有在非零率足够低且索引分布不极端稀疏的情况下,稀疏编码才能带来稳定的收益。务必在真实数据上做小规模试验并监控查询延迟、IO 与 CPU 使用。实现细节与常见问题解答 为什么使用 1 开始的索引 DuckDB 数组类型约定使用 1 为起始下标,这与函数设计保持一致以降低语义混淆。使用者在准备 inds 数据时需注意这一点,避免因 0/1 索引差异导致偏移错误。
如何高效地查询某个特征是否存在 若需判断某个特征 i 是否存在于稀疏向量中,可仅扫描 inds 列并用数组包含或数组交集的表达完成快速筛选,从而避免 vals 的读取。对大型数据集,这种基于索引的预筛选能显著降低后续聚合的计算压力。在聚合时如何避免内存爆炸 使用 agg_array_sum 对大量数组做按位求和时,若数组维度极高,聚合过程会消耗较多内存。为降低风险,可以先对索引进行分桶或分片聚合,或者采用先合并稀疏索引再生成密集数组的分段策略。将聚合工作分散到多个阶段执行,避免一次性在内存中构造完整的密集矩阵。结语 在数据工程与分析的实践中,稀疏向量表示是一种非常实用且高效的存储与计算方式。
DuckDB 提供的稀疏数组函数集为在 SQL 层面直接操控稀疏向量打开了便捷通道,使得常见的特征筛选、点积计算与向量聚合可以直接在数据库内部完成,减少数据搬移并提升整体系统效率。迁移到稀疏表示需要综合考虑数据分布、压缩行为与查询模式,建议先在样本数据上进行评估与基准测试。将 inds 与 vals 分离存储、把计算推向数据库端、避免不必要的稠密化以及在聚合时采取分阶段策略,是实践中常见且有效的优化方法。通过合理地设计数据存储与查询方式,DuckDB 的稀疏数组函数能够在大规模高维稀疏场景下为系统带来显著的存储与性能收益。 。