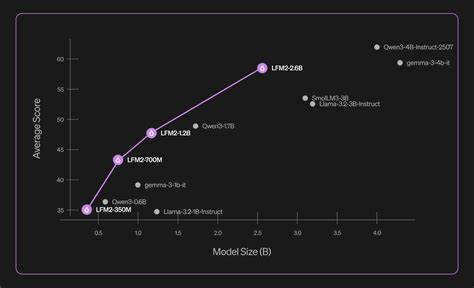
在人工智能领域,语言模型的性能和效率一直是研究与应用的核心焦点。随着模型规模的不断扩大,传统观点认为参数越多,模型的表现越强大。然而,Liquid AI推出的LFM2-2.6B以关键创新打破了这一局限,凭借2.6亿参数的规模,达到了甚至超越了市场上3亿级及以上的语言模型的表现,重新定义了语言模型的效率标准。LFM2-2.6B诞生于Liquid Foundation Model 2系列,继承并优化了此前350M、700M和1.2B模型的优良基因。这款模型在训练过程中吸收了高达10万亿(10 trillion)个标记的数据,涵盖广泛的语料资源与多样化的知识,是其能够在数学推理和指令执行等复杂任务中表现卓越的关键。具体表现方面,LFM2-2.6B在数学推理基准测试GSM8K中取得了82.41%的高分,远超许多规模更大的竞争者。
在指令跟随能力测试IFEval中,同样展现出79.56%的优异成绩,显示其在理解和执行复杂指令方面有着极佳的能力。该模型不仅性能出众,在语言涵盖也非常广泛。开发团队特别针对英语和日语进行了深入调校,同时保持了对法语、西班牙语、德语、意大利语、葡萄牙语、阿拉伯语、中文和韩语等多种语言的高水平支持。多语言的能力使LFM2-2.6B能够在全球范围内广泛应用,适应各类跨文化和多语种的应用场景。在性能之外,LFM2-2.6B的架构设计也是其效率突出的一大亮点。模型采用了混合架构,将分组查询注意力(Grouped Query Attention,GQA)与短卷积层交替排列,这种创新设计大幅提升了推理速度,同时显著减少了键值缓存的需求。
对于实际部署来说,这意味着响应更快,计算资源消耗更低,从而降低了运营成本,提升了商业落地的可行性。在行业应用层面,LFM2-2.6B展现出多场景的适用价值。无论是金融服务中的智能客服和风险评估,还是医疗健康领域的诊断辅助和数据分析,亦或是电商行业的用户交互和个性化推荐,LFM2-2.6B都能提供强有力的技术支持。其灵活的多语言能力为跨国企业的全球扩展提供坚实的技术保障。值得关注的是,LFM2-2.6B采取了开放策略,目前已通过Hugging Face平台以LFM开放许可协议发布,实行开源共享。此举极大降低了开发者和研究者的使用门槛,推动了更广泛的技术创新与合作。
未来,Liquid AI表示将继续致力于扩大基础模型的规模与性能,保持在效率与实力之间的最佳平衡,致力于打造覆盖更多设备和应用场景的智能生态系统。在科技飞速变革的时代,LFM2-2.6B不仅仅是一个语言模型,更代表着以创新驱动效率提升的新风向。它挑战了"大模型即优"的传统观念,证明通过先进架构和精妙设计,较小规模的模型同样能够提供企业级的性能表现。对于企业和开发者而言,选择效率与性能兼顾的模型,将成为未来人工智能应用的关键竞争力之所在。总的来说,LFM2-2.6B依托Liquid AI积累的深厚技术力量,以其小巧却功能强大的特性,正推动语言模型进入一个更加高效、经济和普及的新时代。无论是科研探索还是产业应用,LFM2-2.6B的出现都为人工智能注入了无限可能,期望其能够助力全球开发者和企业开创新的智能未来。
随着人机交互需求的日益增长,高效、准确、响应迅速的语言模型必将成为推动社会信息化进程的重要动力。LFM2-2.6B作为其中的佼佼者,注定将在未来的AI发展中发挥重要作用。 。