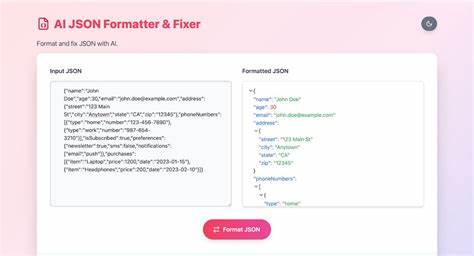
随着人工智能技术的飞速发展,大型语言模型(LLM)如GPT、Claude等在文本生成和数据处理中的应用日益广泛。与此同时,利用这些模型输出结构化数据成为行业热点。然而,LLM生成的JSON格式数据由于模型本身的限制,往往存在诸多格式问题和错误,给开发者的后续处理带来了极大挑战。AI-JSON-Fixer正是在这一背景下诞生的,作为一款专门针对LLM输出的错误JSON进行修复和解析的工具,它以其独特的设计理念和强大的功能为开发者提供了极大便利。通常情况下,LLM在生成JSON数据时常见的问题包括缺失逗号、多余或缺失引号、格式混乱、缺少必要的标点符号以及带有多余的解释性文本等。这些问题导致标准JSON解析器无法正常识别,使得数据提取和使用变得困难。
AI-JSON-Fixer针对这些痛点进行了专门优化,利用纯TypeScript/JavaScript实现,没有任何依赖,保证了工具的轻量和跨平台特性。其核心功能涵盖了从Markdown块中提取JSON、去除有效JSON后面的解释文本、修复未转义的引号、自动检测和添加缺失的逗号,到支持单行和多行JSON格式的灵活解析等。尤其是在应对单行紧凑格式如{"a": 1 "b": 2}及数组格式[1 2 3]时,AI-JSON-Fixer表现出色。安装过程简单,只需通过npm包管理器进行安装即可,方便集成到现有项目中。开发者只需导入LLMJSONParser类,即可对LLM输出字符串进行高效解析,且能自动应用多项修正措施,提升解析成功率。配置选项丰富,支持多种解析模式如严格、标准和激进模式,满足不同场景的需求。
同时,针对引号修复、逗号补充及Markdown内容过滤等常见问题,用户可以根据需要灵活开启或关闭相关功能。AI-JSON-Fixer不仅关注解析准确度,还提供错误修复的追踪能力,帮助用户了解修复过程及信心评分,极大提升了工具的透明度和用户体验。它支持处理包括嵌套对象、数组以及复杂结构在内的多样数据,实现对真实LLM输出的全面覆盖。此外,在开发过程中,项目采用了超过86个测试用例,涵盖大量真实的LLM输出样本,确保稳定性和适应性。对于企业和开源社区来说,AI-JSON-Fixer的零依赖特性与完整的类型定义支持极大提升了维护效率和扩展性,这使得它不仅适合中小型个人项目,也能满足大规模企业级应用的需求。结合实际应用场景,AI-JSON-Fixer特别适合自动化数据采集、对话系统数据后处理、内容生成平台等领域。
比如在聊天机器人生成用户资料或配置时,能够快速转换成可用的标准JSON数据,避免手工调试和格式化,提高开发效率和产品体验。同时,也方便将复杂文本转换为结构化数据,辅助数据分析和业务决策。随着对AI产出内容结构化管理需求的不断增加,工具如AI-JSON-Fixer的市场价值愈加突出。它不仅提升了数据处理的自动化程度,也减少了人工介入的错误率,保障了后端系统的稳定性和准确性。未来,随着LLM模型的不断演进和输出格式的多样化,AI-JSON-Fixer也将持续升级其修复算法和解析策略,以适应更复杂和多变的JSON格式挑战。综上所述,AI-JSON-Fixer是一款结合实用性与创新性的工具,专为解决LLM生成JSON数据中的格式问题而设计。
其完备的修复机制和配置灵活性令其成为开发者处理和解析AI输出JSON数据的首选方案。无论是在研究、开发还是实际运营中,都能帮助用户实现快速、准确且高效的JSON数据转换和应用,为AI与数据处理结合的未来发展提供坚实支持。