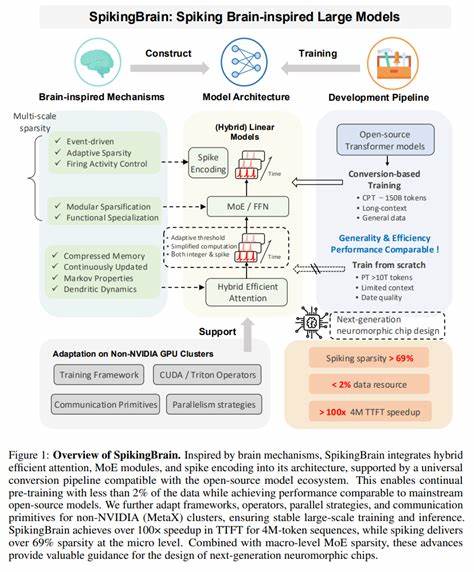
近年来,人工智能领域的快速发展离不开大规模预训练模型的推动。这些模型在自然语言处理、计算机视觉等多个领域展现出强大的能力。然而,随着模型规模的增长,训练与推理的资源消耗急剧增加,传统的计算架构面临着巨大的挑战。为了突破现有瓶颈,研究者们开始借鉴生物大脑的机理,开发更加高效而灵活的计算框架。SpikingBrain即是这一背景下的创新产物,作为一款融合脑启发技术的超大规模模型,它不仅在架构设计上融合了尖端思想,更在训练效率和推理速度上带来了革命性的提升。SpikingBrain的诞生,标志着脑启发式人工智能迈向实用化的重要一步。
SpikingBrain的核心理念源于对人脑信息处理方式的模拟。不同于传统神经网络依靠连续数值信号,脉冲神经网络通过离散的时间脉冲传递信息,更接近自然神经元的工作方式。SpikingBrain以此为基础,结合混合高效注意力机制(hybrid efficient attention)和专家模型模块(Mixture of Experts,MoE),实现了模型在保持性能的同时大幅度减少计算量和数据需求。技术层面上,SpikingBrain采用了通用转换流水线,使其能够兼容现有开源模型生态,极大降低了应用门槛。通过该流水线,SpikingBrain能够利用少于2%的数据持续进行预训练,依然达到与主流开源模型同级别的表现,展现了其极强的学习效率。此外,模型对非NVIDIA硬件环境(如MetaX集群)进行了针对性的框架适配和通信策略优化,确保了大规模训练和推理的稳定性和扩展性。
在推理速度方面,SpikingBrain实现了针对长序列(例如400万Token)的超过100倍推理时间加速,微观层面脉冲稀疏度高达69%以上。结合宏观MoE模块的稀疏激活策略,不仅显著降低了计算复杂度,也为未来 neuromorphic(神经形态)芯片设计提供了宝贵参考,使得硬件层面的效率优化成为可能。在项目结构上,SpikingBrain开源了完整7B参数级模型的实现与权重,涵盖HuggingFace版本、vLLM推理版本以及量化版本,满足不同研究与应用场景的需求。HuggingFace版本方便研究者基于AutoModelForCausalLM快速集成,适配标准语言模型任务。vLLM-HyMeta插件则针对NVIDIA GPU优化,实现模块化的硬件后端集成,显著降低维护成本和加速新硬件接入过程。值得关注的是,W8ASpike量化推理版本通过伪脉冲机制模拟脉冲神经元激活,降低了推理过程的资源消耗,为低精度环境下的部署奠定基础。
虽然当前尚无真正异步事件驱动的硬件支持,但W8ASpike为未来实现真正的脉冲神经网络应用提供了有效的验证平台。在模型资源方面,SpikingBrain提供了多版本的模型权重,包含基础的预训练模型、微调后的聊天模型及视觉语言模型,用户可依照实际应用灵活选择。所有模型权重均托管于ModelScope平台,确保访问便捷,同时示例脚本覆盖从模型加载、推理到聊天交互的全流程,极大简化了上手门槛。从性能评测看,SpikingBrain-7B模型在多个中文基准测试中取得了优异成绩,综合性能媲美甚至超越了许多主流开源大模型。模型在语言理解、推理与生成任务中表现出较强的适应能力,尤其在受限数据条件下的表现展现其高效的预训练策略优势。SpikingBrain的技术突破不仅是学术层面的创新,同时具备广泛的工业应用潜力。
其高效注意力机制与MoE模块的结合方案为对算力资源敏感的应用场景提供了解决方案,如边缘计算、轻量级对话系统和多模态信息处理等。此外,SpikingBrain开源社区积极活跃,持续推动模型代码的优化和硬件适配,为生态系统持续注入活力。未来,随着神经形态计算与异步脉冲神经网络技术的发展,SpikingBrain有望成为研究新一代智能芯片及算法架构的重要基础。综合来看,SpikingBrain通过融合脑启发设计理念和现代深度学习技术,开创了超大规模模型训练与推理的新局面。它在保障性能的同时,实现了训练数据与计算资源的大幅节约,有望引导人工智能向节能、高效和智能的方向不断迈进。面向未来,SpikingBrain不仅为科学界提供了新的研究范式,也为产业界带来了创新动力,推动智能技术加速向实际应用渗透。
作为脑机结合与类脑智能的重要实践,SpikingBrain已然成为新时代大模型发展的重要里程碑,值得每一位人工智能研究者和从业者予以重点关注与深度探索。 。