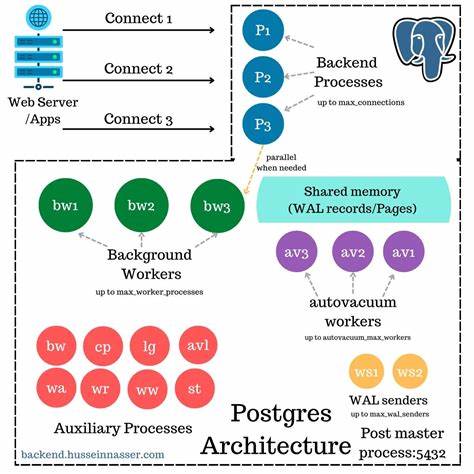
PostgreSQL作为当前最流行的开源关系型数据库系统之一,其稳定性和高性能得益于其复杂而精妙的内部进程架构。深入理解PostgreSQL的进程管理机制,有助于数据库管理员和开发者更好地诊断问题、优化性能,并设计符合实际需求的扩展方案。本文将从PostgreSQL启动开始,一直到服务器关闭的全过程,对其进程架构进行详细解读,为读者揭示背后的运行机制。 在PostgreSQL启动的第一步,用户通过pg_ctl命令启动数据库服务,实际上启动的是"postmaster"进程。Postmaster进程是整个服务器的父进程,负责管理后续所有子进程的启动、运行及结束。postmaster的主函数main()会调用PostmasterMain,完成初始配置和资源分配。
它会解析命令行参数,设置GUC(Grand Unified Configuration,即统一配置参数),确保数据目录和锁文件正常存在且唯一,避免多实例对同一数据目录的冲突。 接下来,postmaster加载共享库,包括核心模块及各种扩展,计算需要的共享内存大小并进行分配。共享内存是PostgreSQL进程间通信和数据共享的基石,它使得不同进程能够高效访问统一的缓冲区和控制信息,避免重复读取和写入。 完成初始化后,postmaster进入它的核心循环 - - ServerLoop。这是一个永不停息的事件循环,监听并等待来自客户端的新连接请求、信号通知或是其他子进程的状态变化。只要ServerLoop终止,整个PostgreSQL实例就会关闭,因此其稳定性极为关键。
在ServerLoop内,postmaster不断检测所有关键进程的状态,如果某些必需的子进程异常退出,它会及时重启这些进程,保证数据库服务的连续性。此外,ServerLoop还负责响应外部信号,例如重载配置、优雅关闭等任务。 PostgreSQL的核心功能高度依赖其众多子进程协同工作。最重要的子进程包括IO worker、checkpointer、background writer、startup进程、wal writer以及autovacuum launcher等。IO worker异步处理页面读取,减轻普通后端进程的压力;checkpointer周期性地将共享缓冲区中的脏页刷新到磁盘,以确保数据持久性;background writer则持续维护共享缓冲区中空闲页面,避免查询进程因缓冲区空缺而阻塞。 server启动时,这些后台进程会被postmaster立即fork创建,保障系统基础功能稳定运行。
随后,根据需求,新的后端进程会为每个客户端连接动态产生。这些后端进程独立处理各自的查询,在共享内存的支持下能够高效读取缓存数据,避免频繁的磁盘I/O。 后端进程如果需要读取内存中不存在的数据页,就会从磁盘加载,但如果共享缓冲区已满,则需先选择某个缓存页进行替换,如果该页被修改过,需要先被刷写到磁盘,才能腾出空间。这种操作可能导致性能波动。为了减轻后端进程的写压力,checkpointer和background writer持续为共享缓冲区腾出空间,使得查询处理更加顺畅。 在复制环境下,PostgreSQL采用特殊的"伪后端"机制。
起初,walreceiver向主节点的postmaster发起"复制"连接请求,postmaster为其fork出新的后端进程。然而,这些后端进程会根据会话启动包的内容改变角色,转变为walsender或walreceiver进程。walsender负责读取主节点的Write-Ahead Log(WAL)并发送给备节点,支持物理和逻辑复制。 除了核心进程,PostgreSQL还支持动态的后台工作进程(background workers),允许用户通过扩展注册自定义的长期运行任务。这类后台工作进程通过shared_preload_libraries指定,并在postmaster的ServerLoop中自动启动和管理。注册机制不仅支持启动时加载,也能实现运行时动态注册,充分增强调度的灵活性。
Postmaster进程还配置了丰富的信号处理机制,以应对运行时各种请求。常见信号如SIGHUP用于重新加载配置文件,SIGTERM和SIGINT则触发不同模式的服务器关闭。通过signal handler的设计,postmaster接收到信号后会设置标志位,进而让ServerLoop中的相应处理函数完成具体操作,保证信号响应的安全和有序。 PostgreSQL支持三种主要的关闭模式,分别是智能(smart)、快速(fast)和立即(immediate)。智能模式会等待所有客户端断开连接后再关闭,适合平滑维护;快速模式则直接终止所有连接并进行正确的清理工作;立即模式则是强制退出,不进行正常的清理,重启后数据库需进行崩溃恢复。这些模式对应着不同的信号策略,符合不同的业务和维护需求。
当子进程结束或崩溃时,postmaster会收到SIGCHLD信号,并启动"收割者"(reaper)机制。reaper负责清理退出进程的相关资源,检测进程状态是否正常。如果发现异常退出,postmaster会采取措施终止所有其他子进程,并根据情况启动崩溃恢复程序。这保证了数据库系统能够及时发现错误并在崩溃后重建数据一致性。 尤其是在恢复模式中,startup进程持续回放WAL文件,确保数据库能够恢复到最近的状态。只有当恢复完成后,postmaster才会允许新的客户端连接,保证数据的可靠性和事务的原子性。
总的来说,PostgreSQL的进程架构体现了分布式协作和高度模块化的设计原则。父进程postmaster作为中央控制节点,不断监督和维护各类子进程,确保数据库服务的稳定与高效。各子进程依据职责清晰分工,从资源管理到查询执行,再到数据复制及后台任务,各司其职且密切配合,共同构建起强大的数据库引擎。 通过对PostgreSQL进程架构的深入理解,可以更有效地应对数据库运维中的复杂场景,也能为优化系统性能提供指导思路。无论是在高并发访问环境下保障响应速度,还是在复制与备份流程中维持数据一致性,这套设计都展现出强大的生命力和灵活度。未来,随着功能和性能的不断扩展,PostgreSQL的进程管理机制仍将是研究和创新的重要方向。
。