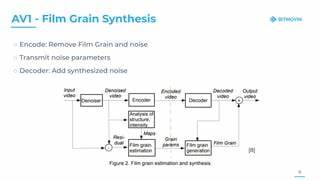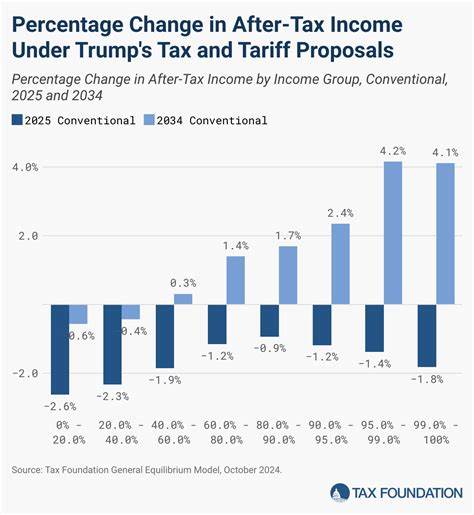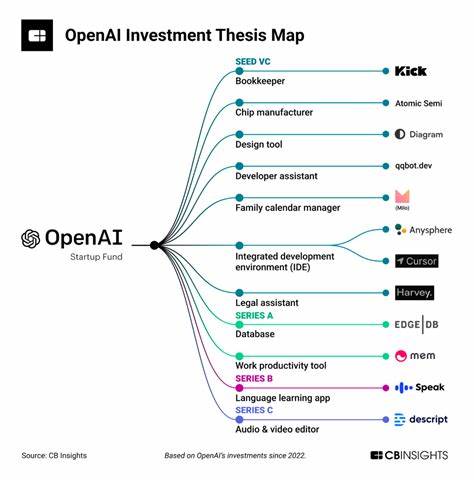
随着人工智能技术的迅猛发展,语言生成模型在各类应用中的表现越来越引人注目。OpenAI与Perplexity作为这一领域的佼佼者,成功打造了能够生成丰富且高质量文本输出的模型,受到了广泛关注。通过对它们微调技术的分析,能够更好地理解当下自然语言处理领域的前沿趋势,以及这些企业如何通过技术创新推动AI语言模型的发展。 在语言模型的世界中,基础模型通常通过大量未标注文本进行训练,具备了强大的语言理解与生成能力。然而,原始训练模型在细节把握、上下文关联性以及针对特定场景的表现上,可能难以达到理想状态。这时,微调技术发挥了关键作用。
微调指的是在预训练完成的基础上,利用特定领域的数据或具备标注的信息进行二次训练,使模型具有更精准和丰富的表现能力。 以OpenAI为例,其著名的GPT系列就在微调过程中采用了大量人类反馈,包括人工筛选与评价等手段。通过引入人类反馈训练(Reinforcement Learning from Human Feedback, RLHF),模型不仅能生成连贯合理的内容,更能遵循道德规范,减少有害或误导信息的产生。实际操作中,OpenAI团队会收集用户交互数据,结合专业标注者的质量评估,持续调整模型权重,从而实现内容输出的优化。这样一来,模型的语义理解更深刻,回答的相关性和准确性显著提高。 Perplexity AI也在微调策略上颇有特色,它强调融合多源知识和动态更新机制,以增强模型的时效性和覆盖面。
通过不断更新训练语料库并结合搜索引擎结果,Perplexity的模型在回答复杂问题时能够调用更为丰富的信息资源。它的微调流程通常涉及对搜索结果的筛选、重新排序以及对生成内容的质量控制,保证输出既有广度又具深度。在某种程度上,它结合了传统知识基础与现代生成技术,为用户提供更具参考价值的答案。 微调技术的核心在于“目标任务的适应性”。不同应用场景需要模型展现不同风格和重点。比如客服机器人需要礼貌和耐心,学术写作助手则讲求严谨与准确。
正因如此,OpenAI与Perplexity在选择微调数据时极为谨慎,既考虑语料的多样性,也注重其代表性和权威性,以避免模型出现偏颇信息或刻板印象。同时,细致的微调流程还涵盖消除重复内容、提升生成内容的连贯度和逻辑性。 技术层面上,微调通常包括监督学习和强化学习两大方法。监督学习依赖于人工标注的数据集,帮助模型学习正确的输入输出映射。强化学习则借助奖励机制,引导模型在生成内容时朝更优目标迈进。OpenAI的策略明显倾向于融合这两种方式,从而充分发挥各自优势,实现更具人性化的输出效果。
Perplexity虽然启用了类似手段,但更注重将实时信息纳入模型运行,确保内容的时效更新。 此外,微调过程中还涉及对生成文本的多维度控制,如长度限制、内容安全过滤和风格调整等。通过对模型概率分布的调整和温度参数的调节,企业能够更灵活地掌控生成结果,防止内容跑偏或过度重复。内容安全则依靠复杂的检测机制和规则引擎,自动识别不合适或敏感信息,保障模型输出符合伦理规范。 理解如何打造丰富输出,也离不开对模型架构的认识。OpenAI的GPT模型基于Transformer结构,具备强大的自注意力机制,能够捕捉长程依赖,提升上下文理解能力。
Perplexity则更多结合多模态信息及知识图谱,增强模型对现实世界知识的映射能力,从而支持复杂问题解答。此外,模型规格的调整、参数量的扩展及计算资源的优化,均为提高输出质量的助力。 从商业角度来看,微调不仅提升了模型的实用性,也大幅拓展了AI产品的应用边界。无论是内容创作、信息检索,还是智能问答与客户服务,精准的微调使得AI系统能够更好地满足用户需求,增强用户黏性并提升盈利能力。OpenAI与Perplexity通过持续投入研发和优化流程,巩固了其竞争优势,推动了整个行业技术水平的提升。 如今,随着用户对AI生成内容质量的期望不断提高,企业对微调技术的探索也愈加深入。
从不断扩充数据库,到引入多轮对话反馈,再到结合人机协作模式,微调策略日益丰富且复杂。未来,基于更强大算力和更智能算法的微调机制,将让语言模型输出更加自然流畅,满足更多元化的应用场景。 综上所述,OpenAI与Perplexity通过结合人类反馈、动态数据更新、多维控制手段及先进的模型架构,成功实现了语言模型的微调,打造出丰富且精准的文本输出内容。这不仅展现了现代人工智能技术的强大潜力,更为未来智能交互奠定了坚实基础。理解这些微调过程,能够帮助业内人士和技术爱好者深入认识语言模型的改进路径,推动AI技术向更智能化和人性化方向迈进。